❌ ELT vs. ETL ❌ Die Unterschiede sowie Vor- und Nachteile der Data-Warehouse-Operationen ETL und ELT ❗
ETL vs. ELT: Unsere Zusammenfassung, Sie urteilen!
Vollständige Offenlegung: Da dieser Artikel von einem ETL-zentrierten Unternehmen verfasst wurde, das sich stark auf die Manipulation großer Datenmengen außerhalb von Datenbanken spezialisiert hat, wird das Folgende vielen nicht objektiv erscheinen. Nichtsdestotrotz soll er dennoch Denkanstöße geben und eröffnet das Wort zur Diskussion.
Seit ihren Anfängen wurden Data-Warehouse-Architekten (DWA) mit der Aufgabe betraut, ein Data-Warehouse mit Daten unterschiedlicher Herkunft und Formatierung zu erstellen und zu bestücken. Aufgrund des dramatischen Wachstums des Datenvolumens stehen dieselben DWAs vor der Herausforderung, ihre Datenintegrations- und Staging-Operationen effizienter zu implementieren. Die Frage, ob die Datentransformation innerhalb oder außerhalb der Zieldatenbank erfolgt, ist wegen der damit verbundenen Leistung, Bequemlichkeit und finanziellen Konsequenzen zu einer kritischen Frage geworden.
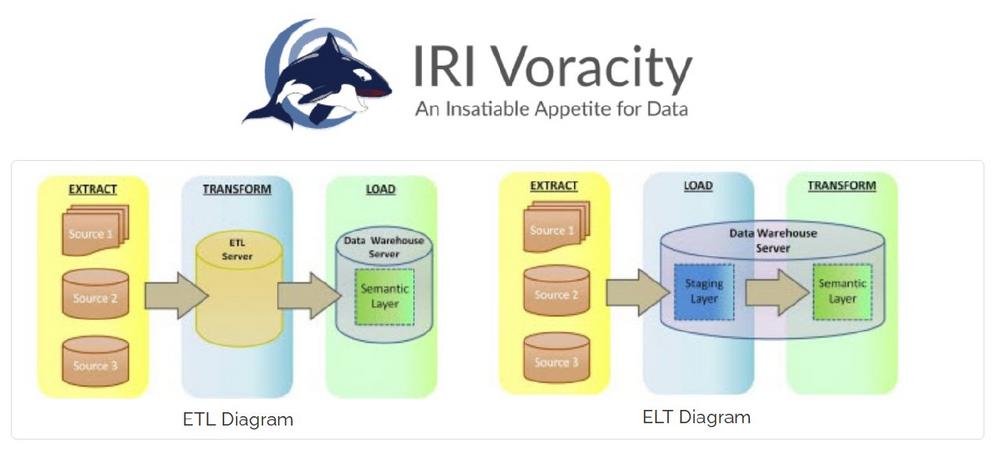
Bei ETL-Operationen (Extrahieren, Transformieren, Laden) werden Daten aus verschiedenen Quellen extrahiert, separat transformiert und in eine DW-Datenbank und möglicherweise andere Ziele geladen. Bei ELT werden die Extrakte in die Single-Staging-Datenbank eingespeist, die auch die Transformationen verarbeitet.
ETL ist nach wie vor weit verbreitet, weil der Markt mit bewährten Akteuren wie Informatica, IBM, Oracle – und mit IRI Voracity, das FACT (Fast Extract), CoSort- oder Hadoop-Transformationen und Bulk-Loading in derselben Eclipse-GUI kombiniert, um Daten zu extrahieren und zu transformieren – floriert. Dieser Ansatz verhindert die Belastung von Datenbanken, die für die Speicherung und den Abruf (Abfrageoptimierung) konzipiert sind, mit dem Overhead einer groß angelegten Datentransformation.
Mit der Entwicklung neuer Datenbanktechnologie und Hardwareanwendungen wie Oracle Exadata, die Transformationen "in a box" verarbeiten können, kann ELT jedoch unter bestimmten Umständen eine praktische Lösung sein. Und die Isolierung der Staging- (laden) und der semantischen (transformieren) Schicht hat spezifische Vorteile. Ein zitierter Vorteil von ELT ist die Isolierung des Belastungsprozesses vom Transformationsprozess, da sie eine inhärente Abhängigkeit zwischen diesen Phasen beseitigt.
Wir stellen fest, dass der ETL-Ansatz von IRI sie ohnehin isoliert, da Voracity die Daten im Dateisystem (oder HDFS) in Etappen anordnet. Jeder für die Datenbank gebundene Datenklumpen kann vor dem (vorsortierten) Laden extern erfasst, bereinigt und transformiert werden. Dies entlastet die Datenbank (sowie BI-/Analyse-Tools usw.) von der Last groß angelegter Transformationen.
Datenmengen und Budgets sind oft ausschlaggebend dafür, ob ein DWA eine ETL- oder ELT-Lösung entwickeln sollte. In seinem IT-Toolbox-Blog-Artikel "So What Is Better, ETL or ELT?" stellt Vincent McBurney seine Vor- und Nachteile beider Ansätze dar, die unten aufgelistet sind mit jeweils einer typische Antwort, die IRI ETL-orientierte Benutzer auf den Punkt bringen:
Vorteile ETL:
- ETL kann die Arbeitslast ausbalancieren und die Arbeitslast mit dem RDBMS teilen – und diese Arbeitslast tatsächlich durch die Transformation von Daten über das SortCL-Programm oder Hadoop ohne Kodierung in Voracity
- ETL kann über Daten-Maps komplexere Operationen in einzelnen Datenflussdiagrammen durchführen – wie bei Voracity-Mapping und Workflow-Diagrammen, die auch kurze, offene 4GL-Skripts gegenüber SQL abstrahieren
- ETL kann mit separater Hardware skaliert werden – bei Commodity-Boxen können Sie die Beschaffung und Wartung selbst vornehmen, und zwar zu wesentlich geringeren Kosten als bei Geräten eines einzelnen Anbieters
- ETL kann Partitionierung und Parallelität unabhängig vom Datenmodell, Datenbank-Layout und der Architektur des Quelldatenmodells handhaben – obwohl die CoSort SortCL-Jobs von Voracity überhaupt nicht partitioniert werden müssen…
- ETL kann Daten im Datenstrom verarbeiten, während sie von der Quelle zum Ziel übertragen werden – oder auch im Batch, wenn dies sinnvoll ist
- ETL erfordert keine Kollokation von Datensätzen, um seine Arbeit zu verrichten – so können Sie bestehende Datenquellen-Plattformen ohne Sorgen um die Datensynchronisation beibehalten
- ETL erfasst heute riesige Mengen an Metadatenabstammung – wie gut oder intuitiv kann eine Staging-DB das tun?
- ETL kann auf SMP- oder MPP-Hardware ausgeführt werden, die Sie wiederum kostengünstiger verwalten und ausnutzen können und sich keine Sorgen über Leistungskonflikte mit der DB machen müssen
- ETL verarbeitet Informationen Zeile für Zeile, und das scheint bei der Datenintegration in Produkte von Drittanbietern gut zu funktionieren – noch besser aber ist die vollständige Block-, Tabellen- oder Datei(en)-Verarbeitung, die Voracity im Volumen durchführt
Nachteile ETL:
- Für ETL-Engines sind zusätzliche Hardware-Investitionen erforderlich – es sei denn, sie laufen auf dem/den Datenbankserver(n)
- Zusätzliche Kosten für den Aufbau eines ETL-Systems oder die Lizenzierung von ETL-Tools – die im Vergleich zu ELT-Geräten immer noch billiger sind, aber noch billiger sind IRI-Tools wie Voracity, die Fast Extract (FACT) und CoSort kombinieren, um ETL ohne diese Komplexität zu beschleunigen
- Möglicherweise verringerte Leistung des zeilenbasierten Ansatzes – richtig, und schneller ist Voracity’s Fähigkeit, Profile zu erstellen, Daten zu erfassen, umzuwandeln und in größeren Brocken auszugeben
- Spezielle Fähigkeiten und Lernkurve, die für die Implementierung des ETL-Tools erforderlich sind – es sei denn, Sie verwenden eine ergonomische GUI wie die von Voracity, die mehrere Job-Design-Optionen in derselben Eclipse-IDE bietet
- Geringere Flexibilität aufgrund der Abhängigkeit vom Hersteller des ETL-Tools – wir sind nicht sicher, wie das verbessert werden kann, wenn man sich stattdessen auf einen einzigen ELT-/Gerätehersteller verlässt; ist die Herstellerunabhängigkeit nicht der Schlüssel zu Flexibilität und Kosteneinsparungen?
- Daten müssen noch eine weitere Ebene durchlaufen, bevor sie im Data Mart landen – es sei denn, der Mart ist nur eine weitere Ausgabe des ETL-Prozesses, wie es für Multi-Target Voracity-Operationen typisch ist
Vorteile ELT:
- ELT nutzt die RDBMS-Engine-Hardware für die Skalierbarkeit – besteuert aber auch DB-Ressourcen, die für die Abfrageoptimierung vorgesehen sind. CoSort- und Hadoop-Transformationen in Voracity nutzen lineare Skalierungsalgorithmen und Aufgabenkonsolidierung, nicht die Speicher- oder E/A-Ressourcen der DB
- ELT hält alle Daten die ganze Zeit im RDBMS – was in Ordnung ist, solange Quell- und Zieldaten in der gleichen DB sind
- ELT wird entsprechend dem Datensatz parallelisiert, und die Platten-E/A wird normalerweise auf Motorebene für einen schnelleren Durchsatz optimiert – ja, aber das gilt noch mehr für externe Transformationen, die nicht mit den Ressourcen des DB-Servers zu kämpfen haben
- ELT skaliert, solange die Hardware und die RDBMS-Engine weiter skalieren können – was kostet wie viel im Vergleich zur obigen Alternative?
- ELT kann das 3- bis 4-fache der Durchsatzraten auf der entsprechend abgestimmten MPP-RDBMS-Plattform erreichen – womit die Appliance im Vergleich zu ETL-Tools ebenfalls auf Voracity-Leistungsniveau liegt, jedoch zu 20-fachen Kosten
- Die ELT-Transformation wird auf dem RDBMS-Server durchgeführt, sobald sich die Datenbank auf der Zielplattform befindet und das Netzwerk nicht mehr belastet wird – die Datenbank (Benutzer) wird also stattdessen belastet?
- ELT hat einfache Transformationsspezifikationen über SQL – die nicht so einfach, flexibel oder funktionsreich sind wie die CoSort SortCL-Syntax oder die Drag-and-Drop-Feldzuordnung in der Eclipse-GUI von Voracity
Nachteile ELT:
- Eingeschränkte Tools mit voller Unterstützung für ELT verfügbar – und zu sehr hohen Preisen für DB-Geräte, die eine hohe Leistung bieten
- Verlust detaillierter Laufzeit-Überwachungsstatistiken und Datenherkunft – insbesondere Metadaten-Auswirkungsanalysen bei Änderungen an verschiedenen Dateien, Tabellen oder unstrukturierten Quellen
- Verlust der Modularität aufgrund des auf einem Set basierenden Designs für die Leistung – und der daraus resultierende Verlust an Funktionalität/Flexibilität
- Transformationen würden Datenbankressourcen nutzen, was sich potenziell auf die BI-Berichtsleistung auswirken könnte – ganz zu schweigen von der Leistung von Abfragen und anderen DB-Operationen
In der Folge entstehen hybride Architekturen wie ETLT, TELT und sogar TETLT, die versuchen, die Schwächen beider Ansätze zu beheben. Aber diese scheinen den bereits so belasteten Prozessen zusätzliche Komplexitätsebenen hinzuzufügen. Es gibt keinen wirklichen Königsweg, und viele Datenintegrationsprojekte scheitern unter dem Gewicht von SLAs, Kostenüberschreitungen und Komplexität.
Aus diesen Gründen wurde IRI Voracity entwickelt, um Daten über das Programm CoSort SortCL in bestehende Dateisysteme oder Hadoop-Fabrics ohne Neucodierung zu integrieren. Voracity ist die einzige ETL-orientierte (aber auch ELT-unterstützende) Plattform, die beide Optionen für externe Datentransformationen bietet. Neben einem überlegenen Preis-Leistungs-Verhältnis bei der Datenbewegung und -manipulation beinhaltet Voracity:
- erweiterte Datentransformation, Datenqualität, MDM und Berichterstattung
- Slowly Changing Dimensions, Change Data Capture, Datenfederation
- Datenprofilierung, Datenmaskierung, Testdatenerzeugung und Metadatenverwaltung
- einfache 4GL-Skripte, die Sie oder Eclipse-Assistenten, Diagramme und Dialoge erstellen und verwalten
- nahtlose Ausführung in Hadoop MR2, Spark, Spart Stream Storm und Tez
- Unterstützung für erwin Smart Connectors (Konvertierung von anderen ETL-Tools)
- native MongoDB-Treiber und Verbindungen zu anderen NoSQL-, Hadoop-, Cloud- und Legacy-Quellen
- eingebettete Berichts-, Statistik- und Prognosefunktionen, KNIME- und Splunk-Anbindungen und Datenfeeds für Analysewerkzeuge
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: +49 (6073) 711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()



