-
 Besser als nur Endpunkt-Sicherheit Der ultimative Schutz für sensible Daten vor internen und externen Bedrohungen
Besser als nur Endpunkt-Sicherheit Der ultimative Schutz für sensible Daten vor internen und externen Bedrohungen 
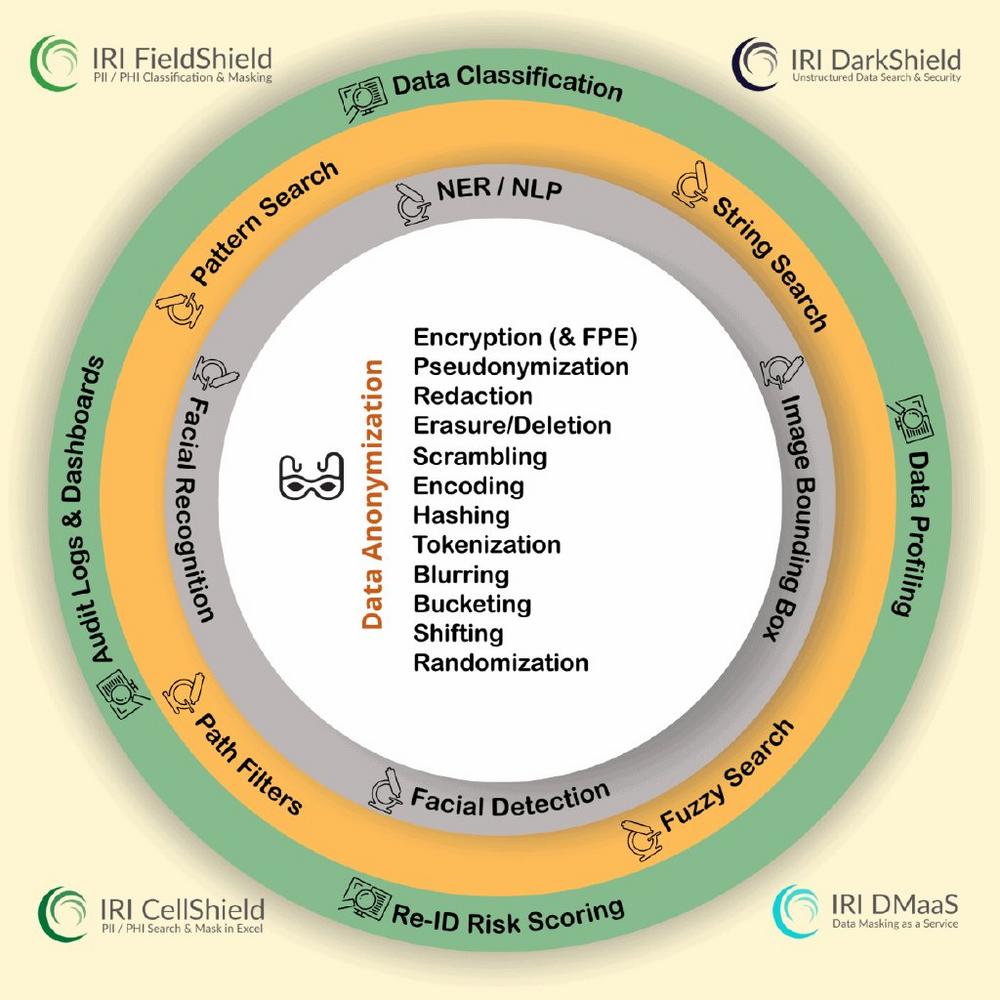
Datenschutz auf Feldebene: Jenseits der Endpunkt-Sicherheit, die durchbrochen werden kann, ist die Verschlüsselung auf Elementebene ein noch besseres Mittel, um sensible Informationen in Datenbanken und Dateien zu schützen. Hier sind 3 Gründe, warum gezielte Verschlüsselung eine entscheidende Datenschutztaktik ist: Vertraulichkeit gewährleisten: Es stellt sicher, dass sensible Daten nur für autorisierte Parteien zugänglich sind, indem Daten in ein für andere ohne den richtigen Entschlüsselungsschlüssel unlesbares Format umgewandelt werden. Datenintegrität bewahren: Durch die Anwendung derselben Verschlüsselungsfunktion auf ähnliche Daten als Regel können Sie sicherstellen, dass der Geheimtext konsistent dem ursprünglichen Klartext entspricht; Verknüpfungen funktionieren weiterhin nach der Maskierung. Kombination verstärkt Schutz: Eine Verschlüsselungsfunktion ist an sich schon leistungsstark, aber wenn sie zusammen…
- Adabas und Natural Migration Erfolgreiches Rehosting von Software AG legacy-Anwendungen nach Linux
Herausforderungen: Wenn Sie große Datensätze direkt aus Software AG Natural sortieren müssen, könnte die native Sortierfunktion möglicherweise nicht die gewünschte Effizienz bieten. Außerdem benötigen Sie möglicherweise eine kostengünstige und bequeme Lösung, um große Dateien zu verarbeiten und Berichte zu erstellen, während Sie Daten zwischen Natural und anderen Anwendungen austauschen. Darüber hinaus kann es notwendig sein, Daten in Adabas-Quellen zu manipulieren, zu maskieren, zu replizieren oder anderweitig zu bearbeiten. Lösungen: IRI CoSort bietet eine Plug-and-Play-Sortierbibliothek für Benutzer von Natural unter Unix. Die CoSort Engine kann bis zu sechsmal schneller sortieren als die native Sortierung. Zusätzlich kann das Datei-Transformations- und Berichtsprogramm SortCL von CoSort direkt aus Natural aufgerufen werden, was eine größere…
- Unstrukturierte Daten Die unverzichtbare Antwort auf Datenschutz und Compliance-Herausforderungen in sensiblen Branchen
175 Zettabyte Dark Data bis 2025: IDC schätzt, dass das Volumen unstrukturierter Daten bis 2025 die schwindelerregende Größe von 175 Zettabyte erreichen wird! Unstrukturierte Daten, die derzeit mindestens 80 % aller Unternehmensdaten ausmachen, stellen Unternehmen weltweit vor große Herausforderungen und Chancen. IRI DarkShield steht bei der Bewältigung dieser Herausforderungen an vorderster Front und bietet eine robuste Lösung zur Sicherung sensibler Daten aus strukturierten, smistrukturierten und unstrukturierten Quellen, sowohl vor Ort als auch in der Cloud. Hier sind einige Gründe, warum DarkShield für Branchen wie Finanzdienstleistungen, Versicherungen, Gesundheitswesen und Behörden unverzichtbar ist: Erweiterte Datensicherheit und Compliance: DarkShield zeichnet sich durch die Identifizierung, Maskierung und Bewertung des Re-Identifizierungsrisikos von sensiblen Daten aus…
- Datenpanne und Datenleck vermeiden Vier bewährte Tips, um sensible Daten rechtzeitig zu schützen
Sensible Daten überall klassifizieren, finden und maskieren: Die preisgekrönte IRI Datenschutz Suite bieten erstklassige Tools zur Klassifizierung, Erkennung und Maskierung sensibler Daten wie PII. Sie helfen bei der Einhaltung von Datenschutzgesetzen wie DSGVO, GDPR, HIPAA und anderen. IRI und autorisierte Partner weltweit bieten maßgeschneiderte Lösungen für Compliance und Sicherheit. Die IRI-Produkte fungieren als umfassende Datenschutz Management Software, die alle Aspekte der Datensicherheit von der Erkennung bis zur Compliance abdeckt, unabhängig von den spezifischen Anforderungen wie GDPR oder HIPAA. 1. Aufspüren sensibler Daten: Definieren und suchen Sie nach PII und anderen vertraulichen Daten in Ihren strukturierten, semistrukturierten und unstrukturierten Quellen vor Ort und in der Cloud. Benutzer von IRI FieldShield (für…
- Nahtlose Business Intelligence Datenverarbeitung und Berichterstellung vereint im gleichen Prozess mit integrierter Datentransformation
Schnelle, unkomplizierte Big Data Berichterstattung: Integration von Reporting in IRI Datenmanagement-Tools ermöglicht direkte Ausführung von BI während ETL-Prozessen! IRI-Nutzer, die umfangreiche Datentransformationen durchführen, können in denselben Jobskripten und I/O-Pässen benutzerdefinierte Detail- und Zusammenfassungsberichte erstellen, was eine nahtlose Verbindung von ETL und BI ermöglicht. Unter Verwendung von IRI NextForm für Datenmigration, IRI FieldShield für Datenmaskierung und IRI RowGen für synthetische Testdaten können dieselben Arten von Berichten generiert werden. Strukturierte sowie semi- und unstrukturierte Datenquellen (alle hier aufgelistet) werden unterstützt, ohne Begrenzung der Anzahl von Quellen oder Zielen. Berichtsspezifikationen können über Texteditor oder über die kostenlose IRI Workbench Eclipse GUI definiert werden, während die Ausführung über verschiedene Schnittstellen wie Befehlszeile, Batch-Skripte oder…
- Datenqualität verbessern Datenaufbereitung und Datenbereinigung beschleunigen, um Zeit und Ressourcen zu sparen
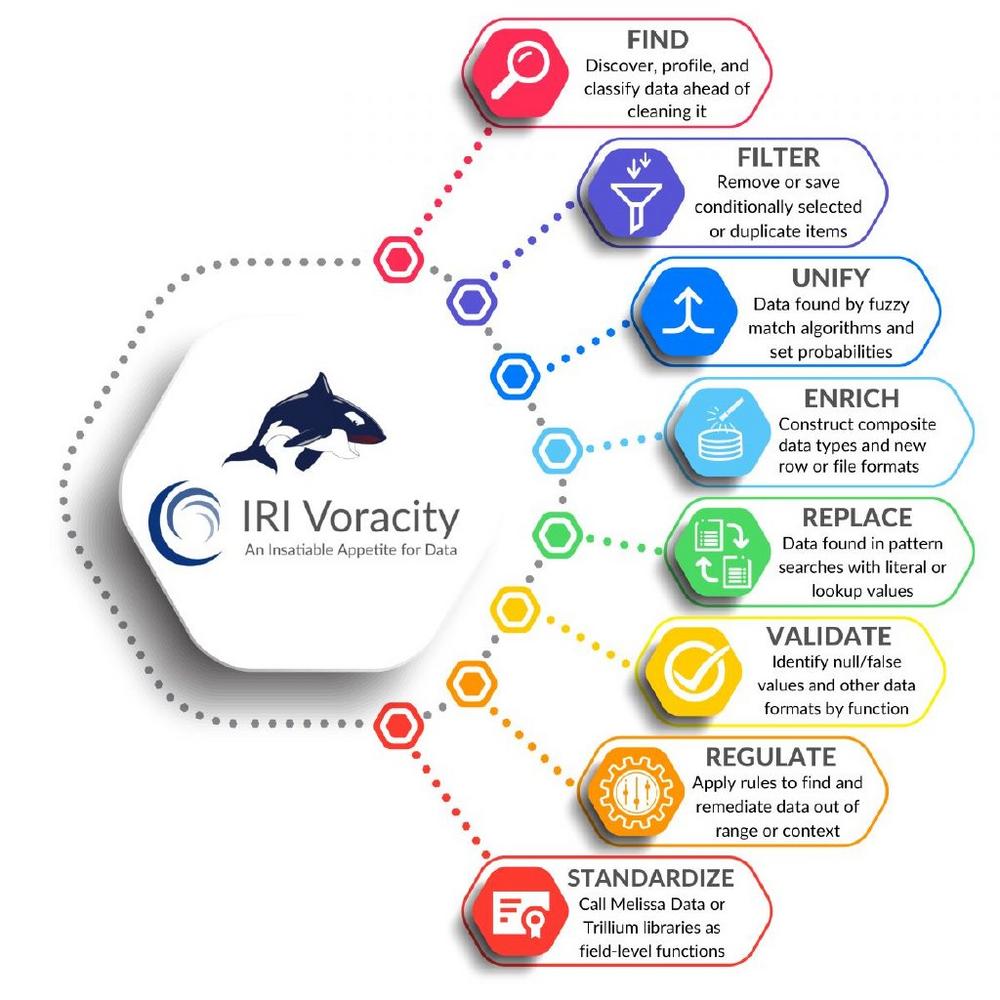
Verbesserung der Datenqualität: IRI betont die Bedeutung von Datenqualität und -verbesserung, da schlechte Datenqualität schwerwiegende Folgen wie irreführende Analysen und gestörte Prozesse haben kann. Unternehmen haben oft die Priorität der Datenqualität vernachlässigt, was zu reaktiven Lösungsansätzen führt, wenn Probleme auftreten. IRI bietet Lösungen, um Datenqualität proaktiv zu verbessern, einschließlich regelmäßiger Überprüfungen und Prozessoptimierung. Die IRI Voracty Plattform bietet Funktionen zur Erkennung, Korrektur und Deduplizierung von Daten, unterstützt durch die IRI Workbench Eclipse GUI. Verschiedene Methoden zur Identifizierung von Duplikaten werden angeboten, einschließlich phonetischer Abgleichsmethoden. Vorlagenstrukturen ermöglichen eine einfache Validierung und Standardisierung von Daten, während Standardisierungsbibliotheken von Drittanbietern integriert werden können. Insgesamt bietet das Voracity-Ökosystem verschiedene Möglichkeiten, Daten zu validieren, anzureichern…
- Datenmigration Umfassende Datenkonvertierung von legacy Daten, die in veralteten Formaten gespeichert sind
Datenreplikation, Datenföderation und Report: IRI NextForm ist eine leistungsstarke und benutzerfreundliche Software für Daten, Dateien und Datenbanken! IRI NextForm wurde aus dem Programm SortCL in IRI CoSort entwickelt und ist eine Datenmigrations- und Neuformatierungssoftware, die Sie bei der Konvertierung und Wiederverwendung von Daten unterstützt, die in alten und modernen Datenbanken, Index- und sequentiellen Dateien, Hadoop und Dark Data (unstrukturierten) Dokumenten gespeichert sind. NextForm eine klügere Alternative zu herkömmlichen Datenmigrations- und Replikationsprodukten sowie Inhouse-Lösungen: Schnelligkeit: IRI NextForm nutzt die Leistungsfähigkeit der IRI CoSort Engine für die effiziente Bearbeitung und Manipulation großer Datenmengen. Mit den gleichen schnellen Ein- und Ausgaberoutinen sowie Datenmanipulationsalgorithmen können NextForm-Anwender umfangreiche Datei- und Tabellendaten schnell konvertieren und ihre…
- Jedes Datensilo schützen End-to-End Datenschutz mit Data Discovery von Dark Data und Datenmaskierung in der Cloud und LAN-weit
Wo sind die sensiblen Daten? Bis zu 90 % der gesammelten oder generierten Unternehmens- und Behördendaten bleiben in unstrukturierten Text- und Bilddateien, Dokumenten und Datenbanken oder anderen so genannten Dark Data-Repositories verborgen. Um das rechtliche, finanzielle und rufschädigende Risiko der Offenlegung personenbezogener Daten (PII) in diesen oft undurchsichtigen Silos zu minimieren und Datenschutzgesetze wie die GDPR einzuhalten, benötigen Sie eine Möglichkeit, die PII in diesen Silos schnell zu lokalisieren und zu sichern. IRI DarkShield zum Auffinden und Maskieren sensibler Daten: Von dem Hersteller der preisgekrönten IRI FieldShield (für strukturierte Datenbank- und Flat-Files) und IRI CellShield (für Microsoft Excel Dateien) Datenmaskierungssoftware ist IRI DarkShield, ein kompatibles und erschwingliches Produkt für die…
- Database Subsetting Kosten- und Sicherheitsprobleme bei vollständiger Datenbankkopie umgehen
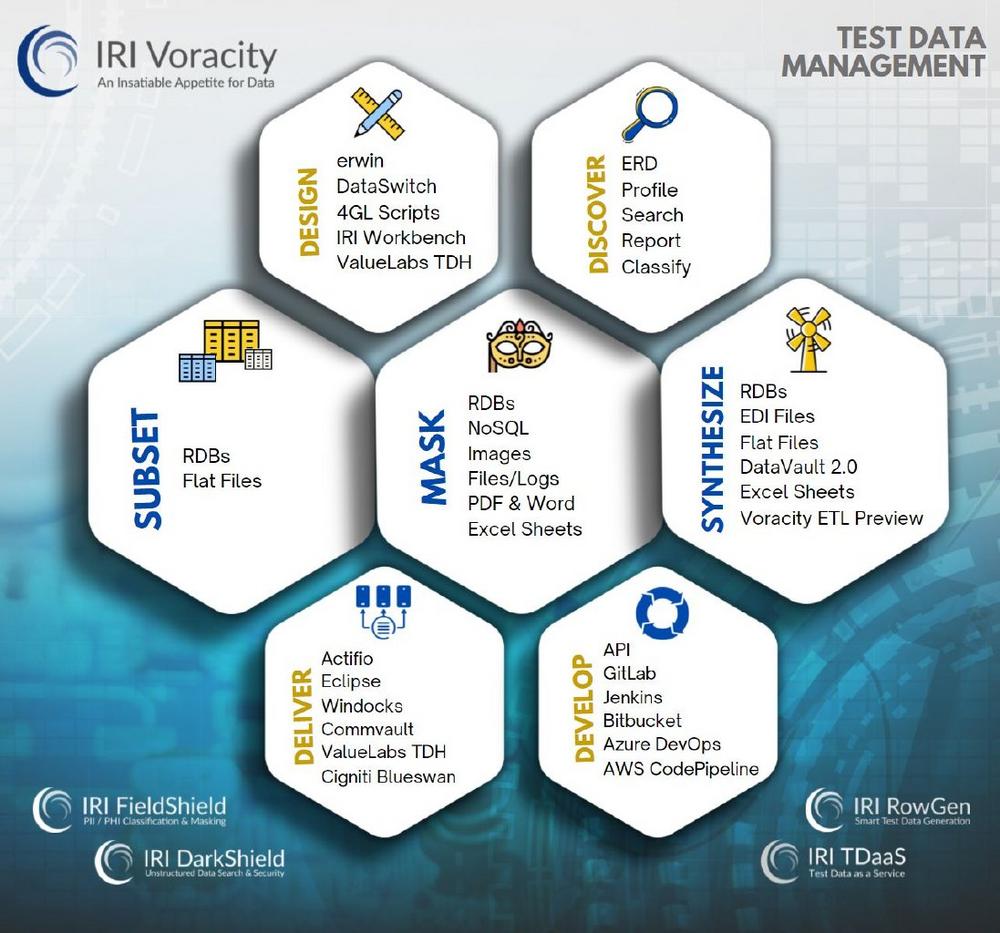
Data Subsetting: Erzeugen einer Teilmenge von Daten! Database Subsetting ermöglicht es, kostspielige und risikoreiche vollständige Kopien großer Datenbanken für Entwicklung, Tests und Schulungen zu vermeiden, indem kleinere, relevante Ausschnitte erstellt werden. Der Prozess des Datenbank-Subsettings beinhaltet die Erstellung einer kleineren, präzisen Kopie einer größeren Datenbank mittels echter Tabellenauszüge. Diese Teilmengen dienen dazu, Kosten und Risiken zu verringern, indem sie entweder mit oder anstelle von Datenmaskierung oder Testdatengenerierung eingesetzt werden. Es ist ein umfangreicher Assistent verfügbar, der den Prozess des Subsettings von Datenbanken beschleunigt und vereinfacht. Dieser Assistent ist für lizenzierte Benutzer der IRI Voracity Datenmanagement-Plattform sowie der Produkte IRI RowGen für synthetische Testdatengenerierung und IRI FieldShield für Datenmaskierung verfügbar.…
- Sensible Daten schützen Gefährdete PII-Daten in un/semi/strukturierten Quellen wie Dark Data finden und schützen
Seit 45 Jahren Pionier im Bereich Big Data Management und datenzentrierter Sicherheit: Die Lösung IRI DarkShield für die Suche und Maskierung von personenbezogenen Informationen (PII) und anderen sensiblen Daten in strukturierten, halbstrukturierten und unstrukturierten Quellen vor Ort und in der Cloud. DarkShield V5 erweitert die Ende 2020 angekündigten Funktionen von V4 erheblich, insbesondere durch Verbesserungen der IRI Workbench GUI für DarkShield. DarkShield 5 das bedeutendste Upgrade in Bezug auf Fähigkeiten, Benutzerfreundlichkeit und Leistung seit der Einführung des Produkts. Es wurde besonderes Augenmerk auf die Benutzerfreundlichkeit und die Notwendigkeit gelegt, konsistente Maskierungsregeln einfach anzuwenden. Im Einzelnen enthält diese Version: DarkShield-API-Funktionalität, die bisher nicht in der IRI Workbench-GUI enthalten war, ist nun…