-
❌ Sensible Daten schützen ❌ Gefährdete PII-Daten in un/semi/strukturierten Quellen wie Dark Data finden und schützen ❗
Seit 45 Jahren Pionier im Bereich Big Data Management und datenzentrierter Sicherheit: Die Lösung IRI DarkShield für die Suche und Maskierung von personenbezogenen Informationen (PII) und anderen sensiblen Daten in strukturierten, halbstrukturierten und unstrukturierten Quellen vor Ort und in der Cloud. DarkShield V5 erweitert die Ende 2020 angekündigten Funktionen von V4 erheblich, insbesondere durch Verbesserungen der IRI Workbench GUI für DarkShield. DarkShield 5 das bedeutendste Upgrade in Bezug auf Fähigkeiten, Benutzerfreundlichkeit und Leistung seit der Einführung des Produkts. Es wurde besonderes Augenmerk auf die Benutzerfreundlichkeit und die Notwendigkeit gelegt, konsistente Maskierungsregeln einfach anzuwenden. Im Einzelnen enthält diese Version: DarkShield-API-Funktionalität, die bisher nicht in der IRI Workbench-GUI enthalten war, ist nun…
-
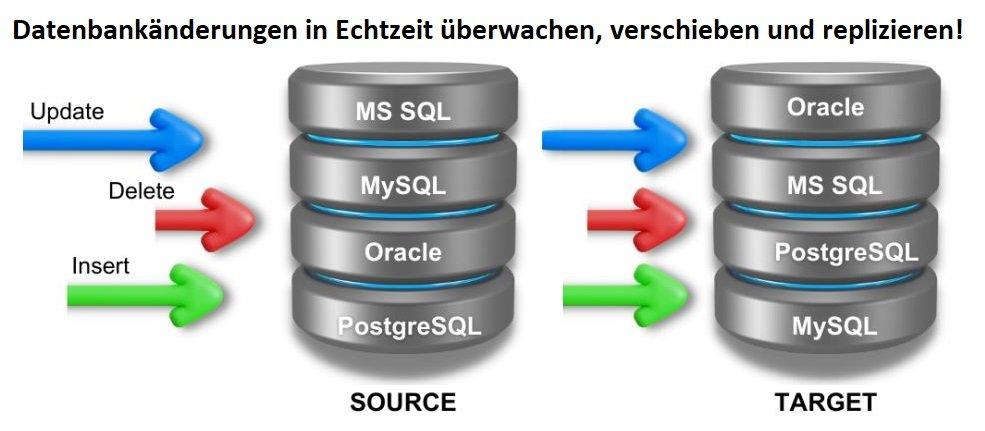
❌ Daten in Oracle Datenbank schützen ❌ Echtzeit-Datenschutz für DSGVO-konforme Datensicherheit basierend auf SQL-Ereignissen ❗
Echtzeit-Datensicherheit: Frühere Artikel erläuterten die statische Datenmaskierung neuer Datenbankdaten mithilfe der /INCLUDE-Logik oder der /QUERY-Syntax in geplanten IRI FieldShield-Job-Skripten, die jedoch Spaltenwertänderungen erforderten, um Aktualisierungen zu identifizieren. Dieser Beitrag präsentiert eine integrierte Methode zur passiven Auslösung von FieldShield-Maskierungsfunktionen auf Basis von SQL-Ereignissen, wodurch eine Echtzeit-Maskierung von Daten ermöglicht wird. Es kann auch als "Prozedurenmodell" für verschiedene Datenbanken und Betriebssysteme dienen. Installation und Anwendungsfälle von FieldShield: Der Artikel beginnt mit der Erläuterung der FieldShield-Installation und den erforderlichen Voraussetzungen. Ein konkretes Beispiel mit PL/SQL-Triggern für die ASCII-formaterhaltende Verschlüsselung und zugehöriger entschlüsselter Ansicht wird vorgestellt. Insgesamt ermöglichen die FieldShield-Maskierungsroutinen und -verfahren, wie PL/SQL, die Maskierung sensibler Daten basierend auf Echtzeit-Datenbankereignissen für verschiedene Anwendungsfälle.…
-
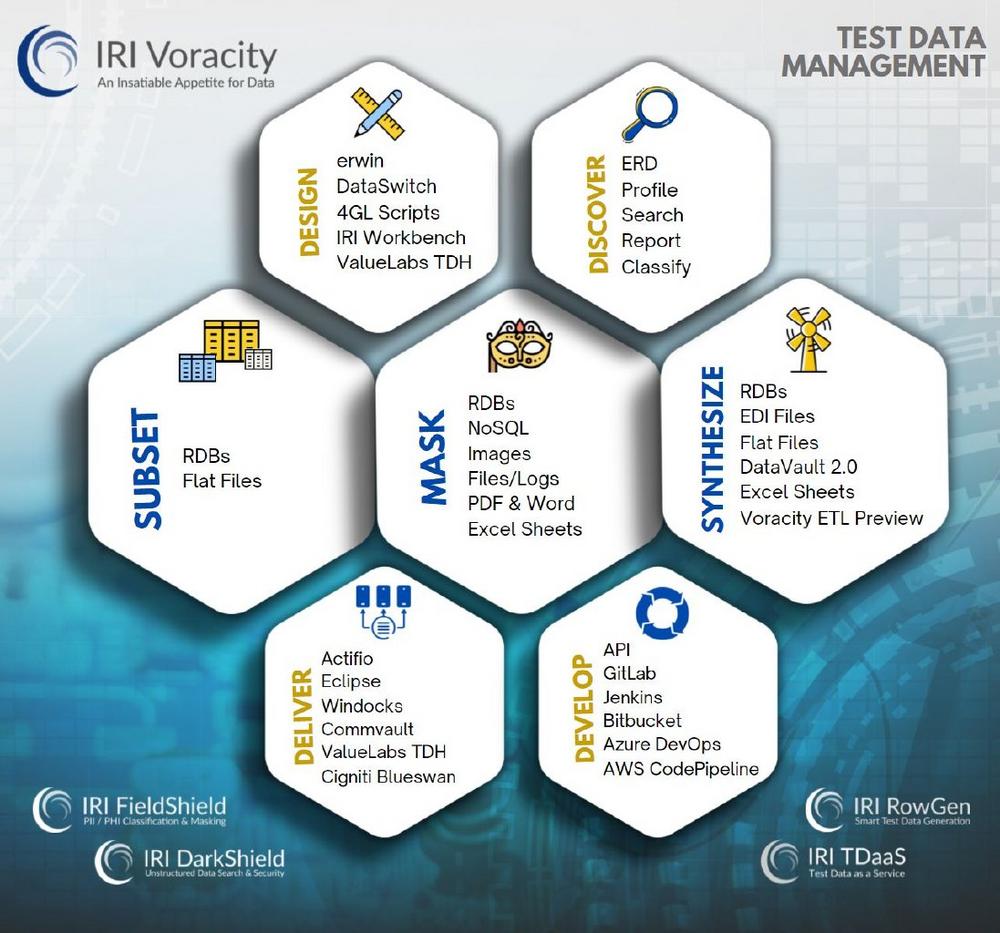
❌ Testdatenmagement ❌ Effektive TDM-Lösung für Datenmaskierung und Generierung synthetischer Testdaten ❗
Effizientes Testdatenmanagement: IRI Voracity bietet eine ganzheitliche Lösung für das Testdatenmanagement (TDM) durch die Integration von Funktionen zur Entdeckung, Klassifizierung und Maskierung sensibler Daten. Die Plattform ermöglicht eine präzise Datenprofilierung und effektives TDM mit verschiedenen Entdeckungsmethoden wie Musterabgleich, benannten Entitäten und Wörterbuchabgleich. Es bietet nicht nur TDM-relevante Funktionen wie Daten-Subsetting und synthetische Testdatengenerierung, sondern auch Funktionen für Datenentdeckung, Klassifizierung und Datenmaskierung. Flexible Plattformnutzung über IRI Workbench und APIs: Die Funktionen können entweder mit der wizard-gesteuerten Eclipse-Benutzeroberfläche IRI Workbench oder via APIs aufgerufen werden. Die Integration mit Partneranbietern wie Windocks und Actifio ermöglicht Datenbankvirtualisierung und nahtlose Integration in Bereitstellungs- und CI/CD-Pipelines. Partnerschaften mit Unternehmen wie Cigniti und ValueLabs verbessern die Workflow-Erfahrung,…
-
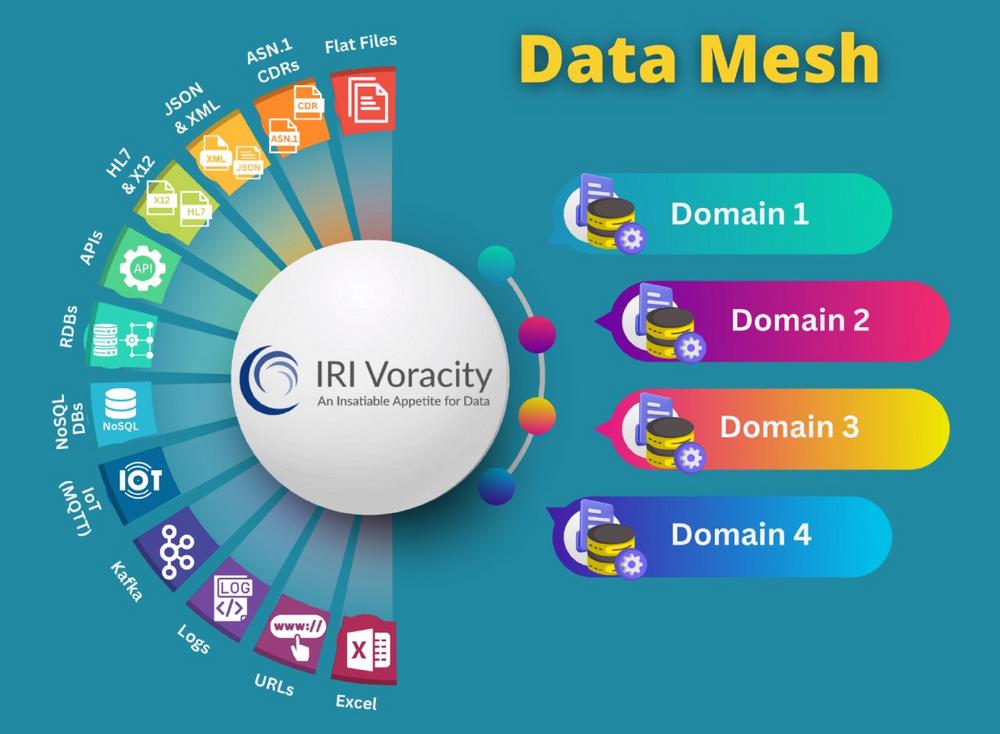
❌ Data Mesh Ansatz ❌ Datenkluft überwinden durch dezentrale Datenarchitektur und Best Practices ❗
Data Mesh: Die Einführung eines Data Mesh-Ansatzes begegnet der wachsenden Kluft zwischen Unternehmen, die ihre datengesteuerten Fähigkeiten verbessern möchten, und den tatsächlichen Daten in ihren Geschäftseinheiten. Engpässe, Silos und organisatorische Hierarchien behindern den benötigten Zugang und die Fähigkeiten. Die Cloud bietet keine Lösung. Unternehmen sehen in Data Mesh eine effektive Möglichkeit, die benötigte Datenmacht zu liefern und sich der Daten-Demokratie zu nähern. Data Mesh, einst akademisch, wird nun Realität. Eine dezentrale Datenarchitektur, laut einer BARC-Studie, wird von 92% der Datenverantwortlichen als sinnvoller angesehen. 19% haben Data Mesh implementiert, und 35% planen dies. Best Practices für erfolgreiches Data Mesh-Design und -Entwicklung umfassen die Bereitschaft zur Transformation, die Prüfung der Eignung, die…
-
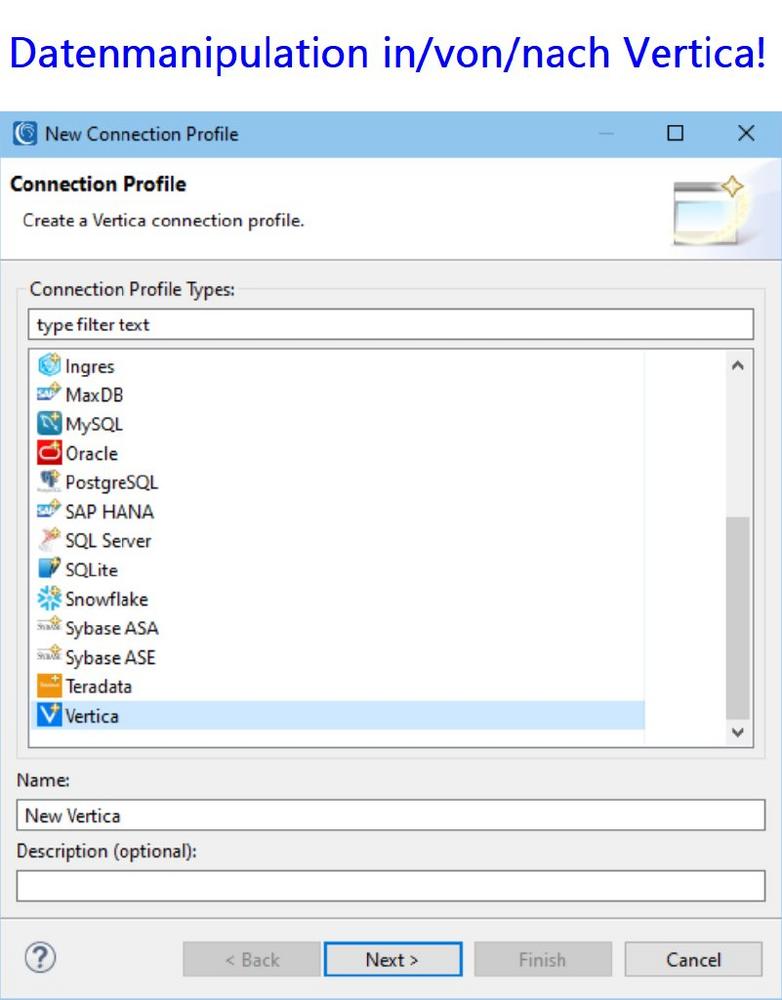
❌ Vertica Datenbank ❌ End-to-End Datenmanagement mit Datenintegration und Datenmigration für schnellere Analysen ❗
Effizientes Big Data Management: In diesem Artikel wird ausführlich erläutert, wie Vertica-Datenquellen gezielt erreicht werden können, indem die IRI Voracity Datenmanagement-Plattform und ihre Ökosystemprodukte verwendet werden. Diese Plattform umfasst verschiedene IRI-Tools, darunter: IRI CoSort: Für die schnellste Big-Data-Manipulation seit 1978. IRI NextForm: Für Datenmigration und -formatierung. IRI FieldShield: Zur Datenmaskierung sensibler Daten in semi/strukturierten Quellen. IRI DarkShield: Zur Datenmaskierung sensibler Daten in semi/unstrukturierten Quellen. IRI RowGen: Zur synthetischen Testdatengenerierung. Der Artikel bietet detaillierte Einblicke in die Erreichung von Vertica-Quellen. Insbesondere werden die erforderlichen ODBC- und JDBC-Verbindungen sowie Konfigurationen erläutert, um Vertica mit der SortCL-Engine und dem IRI Workbench Job Design Client zu integrieren. Diese Konfigurationen sind gemeinsam für die IRI-Softwareprodukte,…
-
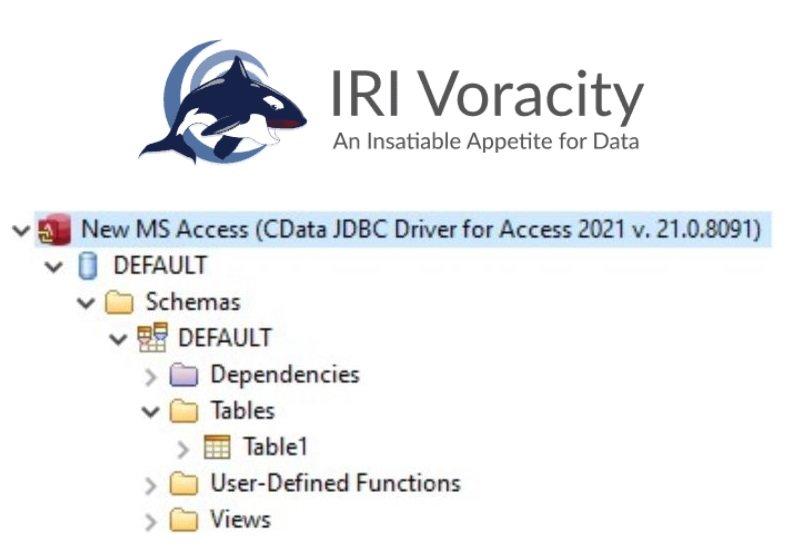
❌ Microsoft Access Datenbank-Software ❌ Umfassende Datenverwaltung und Datenmigration für Datenintegration von/in MS Access DBMS ❗
End-to-End Datenverarbeitung von Microsoft Access: Allein IRI Voracity® bietet die Möglichkeit, eine umfangreiche Bandbreite und Menge an Daten in einer einzigen kostengünstigen Eclipse™-Konsole zu verarbeiten und zu verwalten! Nutzen Sie diese Plattform, um Daten schnell und zuverlässig aus verschiedensten Quellen zu entdecken, zu integrieren, zu migrieren, zu verwalten und zu analysieren – wie auch von Microsoft Access Datenbanken! Barry Devlin von 9sight Beratung äußerte sich zu den Möglichkeiten der IRI Voracity-Plattform wie folgt: ‚Die IRI Voracity-Plattform hat mich veranlasst, die relative Bedeutung der Datenverarbeitung in informationsorientierten Systemen wie Data Warehouses und Data Lakes zu überdenken. Mit den richtigen Funktionen und ausreichender Leistung kann eine Datenverarbeitungsplattform die Funktion der Datenbanken, die…
-
❌ Datenmigration ❌ Datenkonvertierung und Datenformatierung von legacy und modernen Daten ❗
Wechseln von Anwendungen, Hardwareplattformen und Datenbankanbietern: Datenreplikation, Datenföderation und Bericht! IRI NextForm ist das neueste Produkt im Bereich Datenmanagement, das von IRI in Eclipse unterstützt wird. Als Weiterentwicklung SortCL-Programm in IRI CoSort handelt es sich bei IRI NextForm um eine Software für Datenmigration und -formatierung. Sie ermöglicht die Konvertierung und Wiederverwendung von Daten, die in legacy- und modernen Datenbanken, Index- und sequenziellen Dateien, Hadoop- sowie Dark Data (unstrukturierte) Dokumenten gespeichert sind. Mit NextForm können Sie Ihre Daten auf neue Weise anwenden und anzeigen – sei es in neuen Dateien und Tabellen, benutzerdefinierten Berichten, BI-Tools, virtualisierten Ansichten und mehr. NextForm verarbeitet Daten in all diesen Bereichen: 1. Dateiformate: CSV Delimited Text…
-
❌ Datenschutzlösungen ❌ Datenschutz gemäß der nationalen DSGVO, internationalen GDPR und globalen Compliance ❗
Einhaltung von Datenschutzvorschriften zum Schutz personenbezogener Daten: Datenschutzkonformität, insbesondere im Kontext der EU-DSGVO, ist von großer Bedeutung, da Verstöße mit erheblichen Geldstrafen geahndet werden können. Der Schutz personenbezogener Daten ist weltweit ein relevantes Anliegen, wobei die DSGVO als Vorbild für ähnliche Gesetze dient. Datenschutzgesetze zielen darauf ab, den Menschen die Kontrolle über ihre persönlichen Informationen zurückzugeben, haben jedoch auch Auswirkungen auf die internationale Datenbewegung. Die Implementierung solcher Gesetze ist bilateral, erfordert also die Zustimmung von Ländern, die Daten austauschen. Die Durchsetzung von Datenschutzgesetzen erfordert nicht nur technische Maßnahmen, sondern auch eine effektive Datenschutzkultur in Unternehmen. Diese Informationen sind besonders relevant für Manager in Unternehmen, die Datenschutzgesetzen unterliegen, sowie für Mitarbeiter,…
-
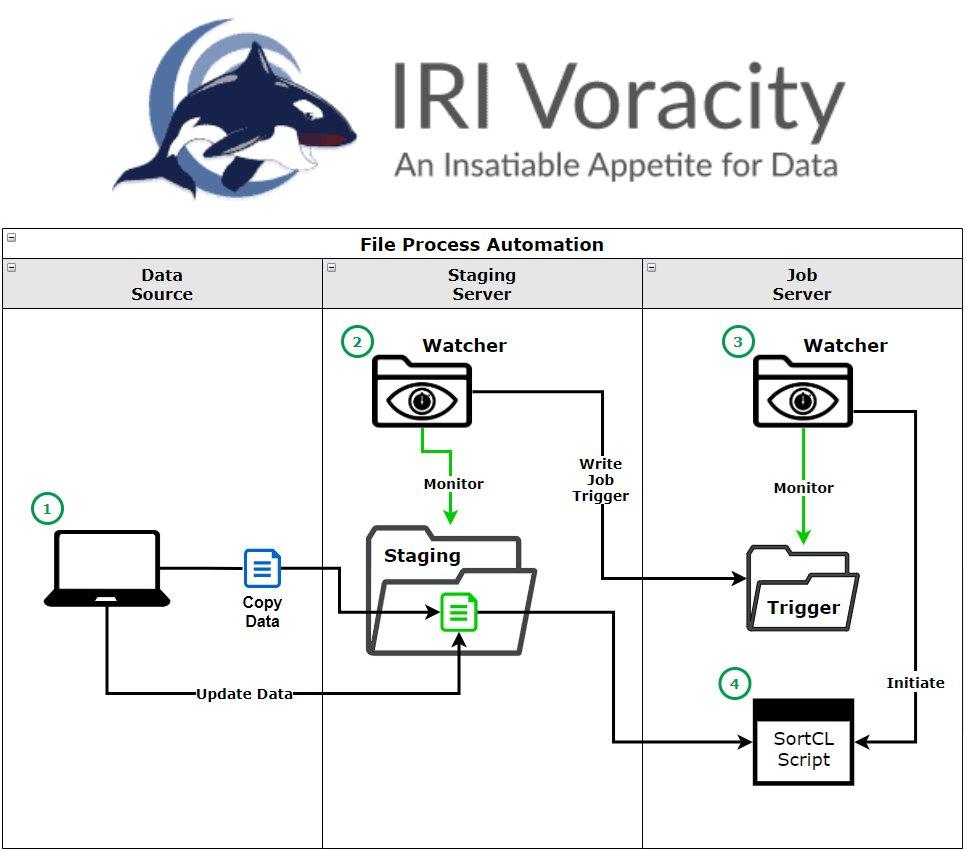
❌ Echtzeit Dateiüberwachung ❌ POC um Jobs automatisch durch Änderungen in den Quelldateien auszulösen ❗
Automatisierung von Datenmanagement: Lösung zum Auslösen von Jobs bei Echtzeit-Änderungen von Daten in relationalen Datenbanktabellen! Das manuelle Auslösen von SortCL-kompatiblen Jobs in IRI Voracity ETL-, IRI CoSort Reporting-, IRI FieldShield Datenmaskierung- oder IRI NextForm-Migrationsszenarien ist in Umgebungen, in denen Daten in Quellen dynamisch hinzugefügt oder geändert werden, weder realistisch noch produktiv. Im Gegensatz dazu macht die Automatisierung von Aufträgen in Echtzeit manuelle Aufrufe überflüssig und stellt sicher, dass die richtigen Aufträge rechtzeitig ausgeführt werden. Datei-Überwachung Übersicht: Die Dateiüberwachung wird im Allgemeinen dazu verwendet, um festzustellen, ob eine Datei in einem Verzeichnis erstellt, geändert, umbenannt oder gelöscht wurde. Die beiden Hauptmethoden, die zur Ermittlung von Änderungen in einem Verzeichnis verwendet werden…
-
❌ Datenbankreorganisation ❌ Reorg von Datenbanken um Datenbankleistung zu verbessern und Speicherplatz zu sparen ❗
Datenbank-Reorganisationen: Datenbankreorganisationen werden durchgeführt, um Datenspeicherplatz zu sparen und die Effizienz sowie Leistung der Datenbank zu verbessern. Dieser Artikel erklärt warum. Der nächste Artikel zeigt, wie man mehrere Tabellen und Datenbanken in Eclipse reorganisiert. Daten in großen RDBMS-Tabellen werden mit der Zeit fragmentiert. Die Größe von Tabellen und Indizes nimmt zu, da Datensätze auf mehr Datenseiten verteilt werden. Mehr Seitenzugriffe und Zeilen in nicht sortierter Reihenfolge während der Abfrageausführung verlangsamen die Abfrageantworten. Um den verschwendeten Platz zurückzugewinnen, die Verfügbarkeit der Datenbank zu verbessern und den Zugriff auf Daten zu beschleunigen (Abfrageantworten), sollten Sie eine Strategie für die Reorganisation Ihrer Datenbankobjekte in Betracht ziehen. Datenbank-Reorganisationen bestehen aus zwei Typen für diese…