-
❌ Datenintegration seit 1978 ❌ Erhöhte Effizienz bei Datenmigration dank schneller ETL-Tools❗
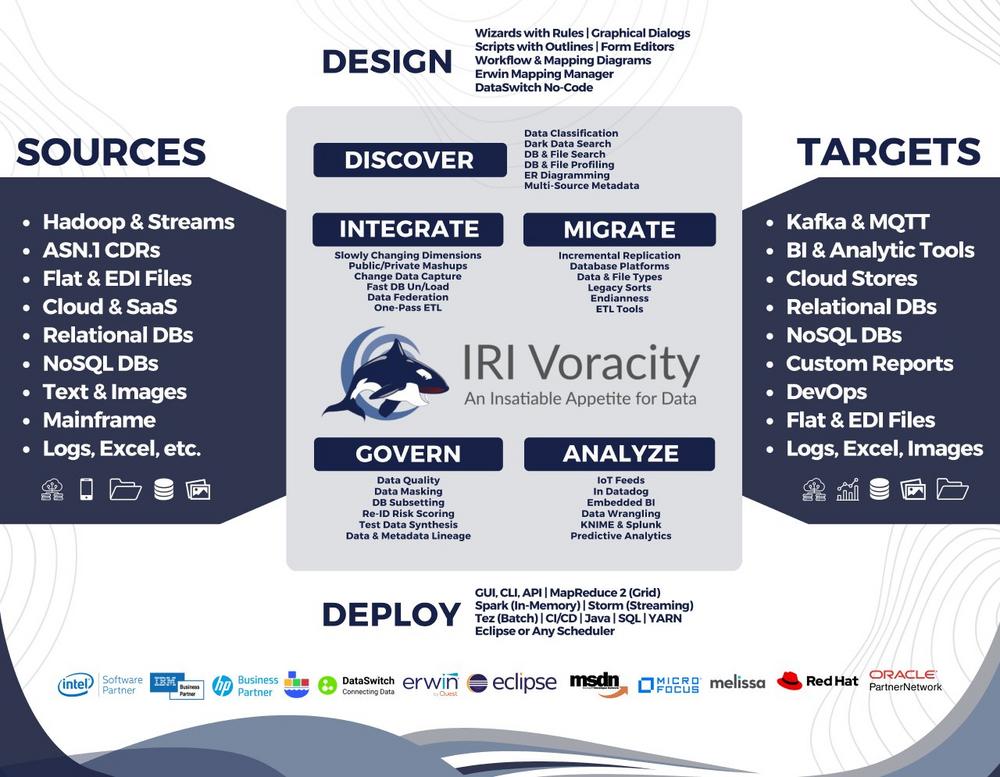
Die leistungsstarke Lösung für die Datenintegration und Datenmigration! IRI ist ein etablierter Anbieter im Bereich Datenmanagement und war seit langem in Datenmodernisierungsprojekten tätig, wie etwa bei der „Lift and Shift“-Methode für Altsysteme. Das Unternehmen begann in den späten 1970er Jahren mit der Durchführung von Mainframe-Sortiermigrationen und hat sich seitdem zu einem Experten in der Datenbewegung, -manipulation und -modernisierung entwickelt. Dies umfasst unter anderem die Konvertierung von Datentypen und Dateiformaten sowie ETL-Operationen mit dem weit verbreiteten CoSort-Daten-Transformationstool. In diesem Zusammenhang bietet IRI auch umfangreiche Funktionen für die Datenintegration. Die Integration von Daten ist eine weitere Form der Datenbewegung, bei der ähnliche Herausforderungen wie bei der Migration auftreten, auch wenn die Nuancen unterschiedlich…
-
❌ Datenlebenszyklus ❌ Sicherer Umgang mit Patientendaten von der Erhebung bis zur Löschung (DLCM) ❗
Angesichts wachsender Datenmengen und strenger Datenschutzbestimmungen steht das Gesundheitswesen vor einer entscheidenden Frage: Wie lassen sich sensible Patientendaten gezielt schützen, ohne die Effizienz von Forschung und Versorgung zu beeinträchtigen? Der Schutz personenbezogener Gesundheitsinformationen ist unerlässlich, um Vorschriften wie HIPAA, DSGVO und andere gesetzliche Anforderungen zu erfüllen. Gleichzeitig erfordert die digitale Transformation des Gesundheitswesens leistungsfähige Big-Data-Lösungen, um Daten effizient analysieren und nutzen zu können. Die Fähigkeit, personenbezogene Gesundheitsinformationen (PHI) effizient und umfassend zu anonymisieren, ist mittlerweile eine kritische Anforderung im Gesundheitswesen. Angesichts der zunehmenden Menge an Gesundheitsdaten ist es erforderlich, Lösungen zu finden, die sich nahtlos in bestehende IT-Infrastrukturen integrieren lassen. Der Schutz sensibler Patientendaten und eine effiziente Verwaltung des Datenlebenszyklus…
-
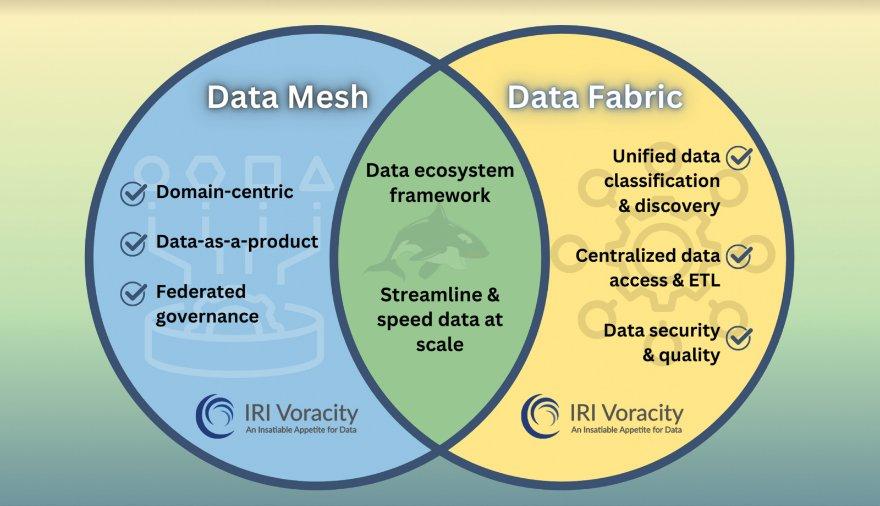
❌ Data Fabric und Data Mesh ❌ Vereinfachte Datenverwaltung für direkte Nutzung ohne Zwischenspeicherung ❗
Effiziente Datenverarbeitung für alle Branchen: Seit 1978 optimiert IRI Inc. die Datenverarbeitung für Unternehmen in verschiedenen Bereichen, darunter Banken, Regierungen, das Gesundheitswesen, Telekommunikation, Einzelhandel und Energie. IRI Voracity zeichnet sich durch seine Fähigkeit aus, komplexe Datenprozesse zu bewältigen, sensible PII-Daten in mehreren Quellen zu identifizieren und zu maskieren sowie ETL-Prozesse effizient durchzuführen. Die Plattform nutzt Datendefinitionsdateien (DDF), um Datenquellen mit Zielsystemen zu verknüpfen, Geschäftsregeln anzuwenden und Nachverfolgbarkeit sicherzustellen. Die leistungsstarke SortCL-Engine ermöglicht Datenintegration, -transformation, -bereinigung und -maskierung – lokal, in der Cloud oder in hybriden Umgebungen. Die intuitive Eclipse-basierte IRI Workbench bietet eine benutzerfreundliche Oberfläche für umfassendes Datenmanagement. Data Fabric und intelligente Datenverwaltung ohne Zwischenspeicherung: IRI Voracity unterstützt moderne Data-Fabric-Architekturen,…
-
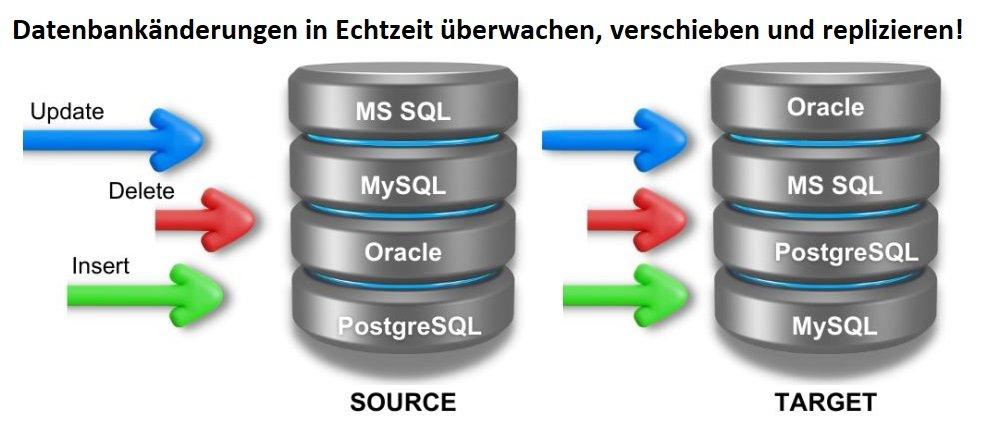
❌ Datenreplikation in Echtzeit ❌ Effiziente und gezielte Datenübertragung durch Change Data Capture (CDC) ❗
Effiziente Datenübertragung und Replikation mit Change Data Capture (CDC): Change Data Capture (CDC) ermöglicht eine gezielte Übertragung von Rohdaten aus Produktivsystemen in Analyseanwendungen, um diese zu entlasten und Echtzeiteinblicke zu liefern. Durch den Einsatz von ETL-Prozessen und Metadaten werden Daten gefiltert, transformiert und geladen, während automatisierte Abläufe für eine hohe Effizienz sorgen. Um eine zuverlässige Datenpipeline zu gewährleisten, nutzt CDC verschiedene Methoden zur Erfassung und Bereitstellung von Datenänderungen. Es erkennt Inserts, Deletes, Updates sowie DDL-Änderungen in Produktivsystemen und überträgt diese an Zielsysteme – von klassischen Datenbanken über Public-Cloud-Dienste bis hin zu Data Warehouses, Data Lakes und Microservices. Mit IRI Ripcurrent, einer neuen Funktion der Datenmanagementplattform IRI Voracity, wird nun auch…
-
❌ Sichere und hochwertige Daten für Künstliche Intelligenz ❌ Erfolgreiche KI-Modelle beginnen mit bereinigten Daten ❗
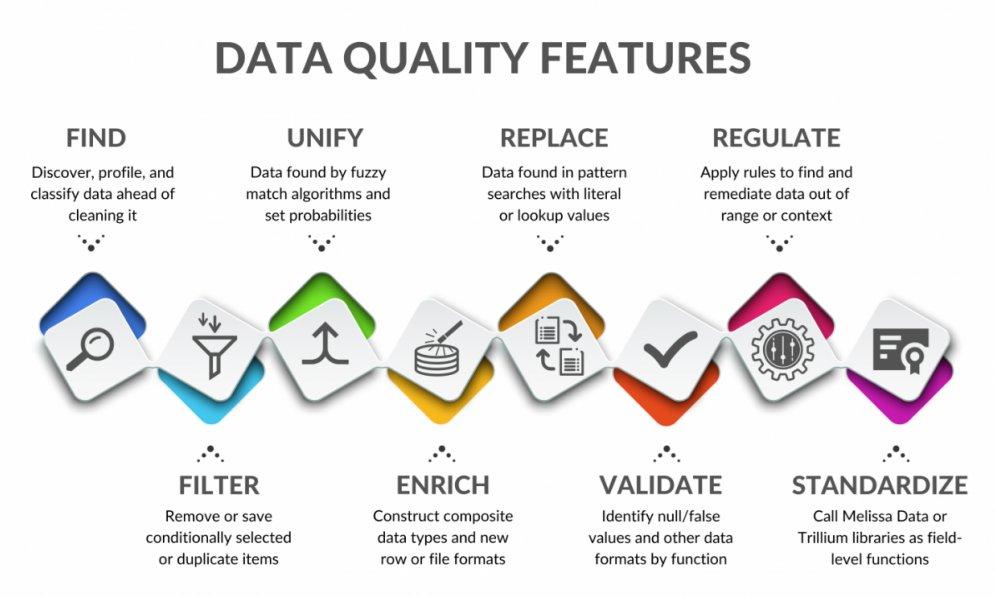
Optimierung und Schutz von Daten für KI-Systeme: In diesem Artikel werden die vielseitigen Einsatzmöglichkeiten der Datenbereinigungs- und Maskierungslösungen von IRI Voracity vorgestellt. Ziel ist es, die Qualität und Sicherheit von KI-Modellen zu erhöhen – insbesondere für Anwendungen mit reaktiven Maschinen oder speicherbegrenzten KI-Systemen, die auf verlässliche und geschützte Daten angewiesen sind. Künstliche Intelligenz (KI), insbesondere Generative KI (GAI), hat in diesem Jahr enorme Aufmerksamkeit erregt. Sowohl die Technologiebranche als auch die breite Öffentlichkeit zeigen großes Interesse – mit teils begeisterten, teils kritischen Reaktionen. Viele Unternehmen, innerhalb und außerhalb der Softwarebranche, planen daher, GAI in naher Zukunft gewinnbringend einzusetzen. Diese Entwicklung bietet großes Potenzial, birgt jedoch auch Risiken. Unternehmen könnten in…
-
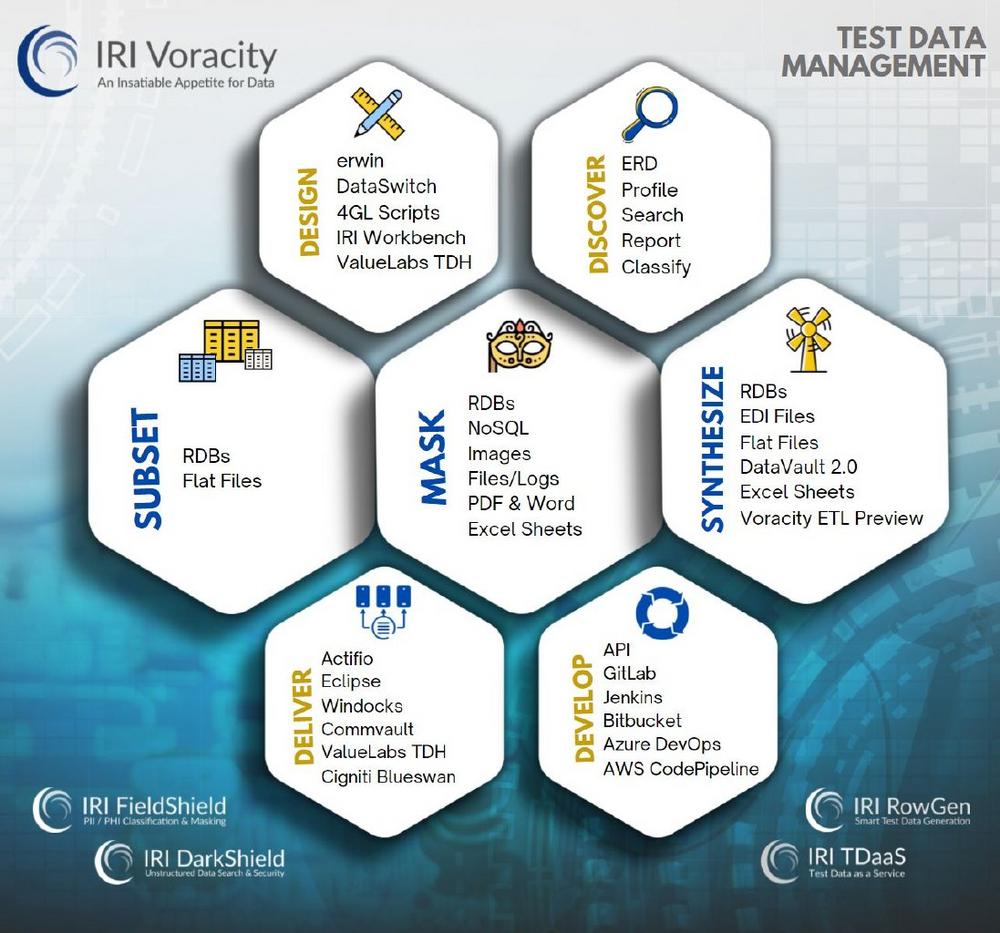
❌ Database Subsetting ❌ Reduzierung von Kosten und Risiken durch gezieltes Data Subset (Teilmenge), anstatt vollständige Datenbankkopie ❗
Effizientes Database Subsetting: Präzise Teilmengen statt kompletter Kopien! Mit Database Subsetting vermeiden Sie kostspielige und risikobehaftete vollständige Datenbankkopien für Entwicklung, Tests und Schulungen. Stattdessen werden gezielt relevante Ausschnitte erstellt – echte Tabellenauszüge, die Kosten senken und den Datenschutz erhöhen. Diese Teilmengen lassen sich flexibel mit Datenmaskierung oder Testdatengenerierung kombinieren, um sensible Informationen zu schützen. Ein leistungsstarker Assistent beschleunigt den Subsetting-Prozess und vereinfacht die Erstellung korrekter Teilkopien. Verfügbar in der IRI Voracity Plattform sowie in den Tools IRI RowGen (synthetische Testdaten) und IRI FieldShield (Datenmaskierung), unterstützt er Nutzer bei der Auswahl der Quelldaten, Sortierung, Zieltabellen und Sicherheitsoptionen. Die generierten Skripte ermöglichen es, präzise Subset-Tabellen oder Flat-Files effizient zu erstellen. Dynamische…
-
❌ Rehosting von Adabas und Natural ❌ Mainframe-Anwendungen erfolgreich auf Linux migrieren ❗
Optimierte Datenverarbeitung und Sicherheit für Adabas & Natural Die native Sortierfunktion von Software AG Natural stößt bei großen Datensätzen oft an ihre Grenzen. Unternehmen benötigen eine leistungsstarke, flexible und kosteneffiziente Lösung zur Verarbeitung großer Dateien, zur Berichtserstellung und zum Datenaustausch zwischen Natural und anderen Anwendungen. Auch das Manipulieren, Maskieren, Replizieren und Bearbeiten von Adabas-Daten stellt eine Herausforderung dar. Mit IRI CoSort erhalten Natural-Nutzer unter Unix eine leistungsstarke Sortierbibliothek, die bis zu sechsmal schneller arbeitet als die Standardfunktion. Das SortCL-Programm von CoSort kann direkt aus Natural aufgerufen werden und ermöglicht erweiterte Datei- und Datenverarbeitung. Zudem lässt sich CoSort nahtlos in die von Tetrad Systems entwickelte Legacy-Plattform "Operational Processing for Unix"…
-
❌ Optimierte Snowflake-Datenprozesse ❌ Schnellere Datenintegration, mit Datenbereinigung und optionaler Datenmigration ❗
Maximale Effizienz für Ihre Snowflake-Datenverwaltung: Optimieren Sie Ihre Snowflake-Prozesse mit den leistungsstarken Lösungen von IRI. Unsere flexiblen Tools für Datenintegration, -bereinigung, -migration und -replikation ermöglichen eine schnelle, kosteneffiziente und sichere Verwaltung Ihrer Daten. Für eine verbesserte Datenqualität sorgt IRI CoSort durch die Vorsortierung von Flat-Files, wodurch Clustering und Abfragen effizienter werden. IRI NextForm erleichtert die Datenmigration, Replikation sowie individuelle Berichterstellung und Tabellenbefüllung. IRI FieldShield schützt sensible Daten zuverlässig, während IRI RowGen realistische Testdaten für Snowflake generiert. Nutzen Sie diese Lösungen einzeln oder als Teil der IRI Voracity-Plattform, um Ihre Snowflake-Datenprozesse ganzheitlich zu optimieren! Effiziente Datenverarbeitung: Unsere bewährte Software für Datenmanagement und Datenschutz vereint modernste Technologien mit über 40 Jahren Erfahrung in…
-
❌ Migration von Daten ❌ Robuste Lösung für die Datenmigration und umfangreiche Funktionen für die Datenintegration ❗
. Skalierbare Lösungen: IRI bietet mit der Voracity-Plattform und anderen Lösungen eine umfassende und bewährte Unterstützung für Datenmigration, Datenintegration und Datenmanagement. Das Unternehmen verfügt über mehr als vier Jahrzehnte Erfahrung und hat sich insbesondere durch Projekte zur Modernisierung von Altsystemen einen Namen gemacht. Bereits in den 1970er Jahren begann IRI mit der Unterstützung von Mainframe-Migrationen und entwickelte sich zu einem führenden Anbieter von Lösungen für die Bewegung, Manipulation und Modernisierung von Daten. Die Plattformen von IRI bieten dabei nicht nur Werkzeuge zur Datenmigration, sondern auch umfassende Funktionen zur Datenintegration, die modernste ETL-Prozesse (Extract, Transform, Load) unterstützen. Datenintegration und Datentransformation: Die auf CoSort basierende Voracity-Plattform ermöglicht schnelle und effiziente Extraktion und…
-
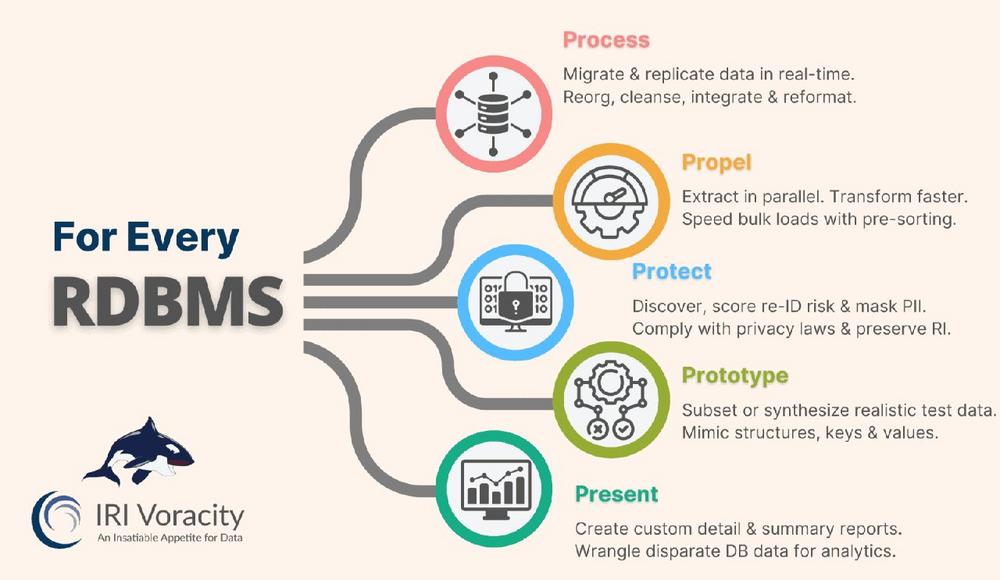
❌ Relationale Datenbank RDBMS ❌ Effizientes Verschieben und Maskieren von Datenbank-Daten ❗
Datenbank-Daten verschieben und maskieren: Performance und Datenschutz optimieren! Datenbanken sind das Herzstück moderner IT-Infrastrukturen und spielen eine zentrale Rolle in nahezu allen Geschäftsprozessen. Doch langsame Abfragen, ineffiziente Datenverarbeitung und steigende Systemanforderungen können die Performance erheblich beeinträchtigen. Mit zunehmendem Datenvolumen stoßen viele Unternehmen an ihre Grenzen: Langsame Abfragen, die Geschäftsprozesse verzögern Hohe Systemlast, die Serverressourcen übermäßig beansprucht Datenmigrationen, die riskant und zeitaufwendig sind Ineffiziente ETL-Prozesse, die wertvolle Rechenleistung verschwenden Sicherheitsrisiken, die durch ungeschützte oder fehlerhafte Datenbankoperationen entstehen Leistungsstarke Technologien helfen Datenbanken zu optimieren und Engpässe zu beseitigen: Beschleunigung von Abfragen: Durch intelligentes Indexing, Partitionierung und Query-Optimierung können Datenbankabfragen signifikant beschleunigt werden. Dies sorgt für schnellere Datenanalysen und minimiert die Belastung Ihrer…