-
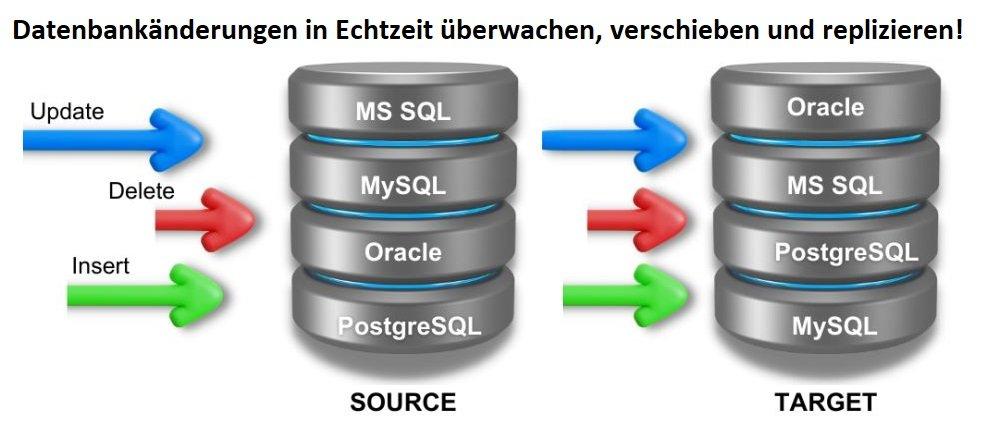
❌ Datenintegration in Echtzeit ❌ CDC überträgt Daten aus verschiedenen Quellen in Echtzeit für Datenanalyse und Berichte ❗
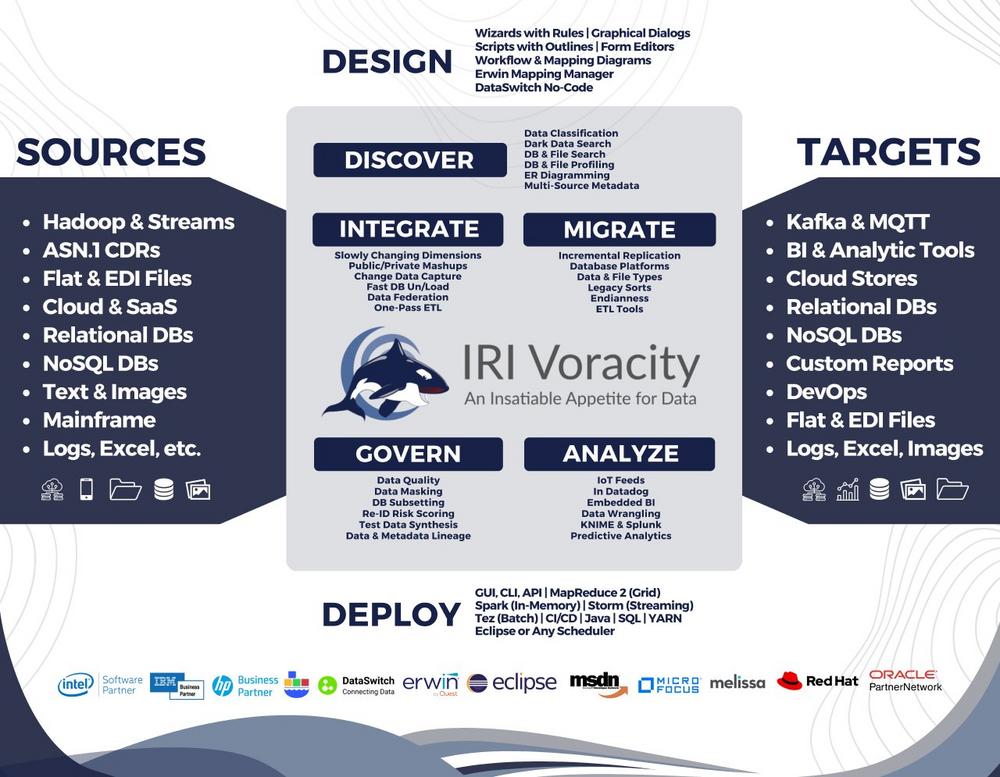
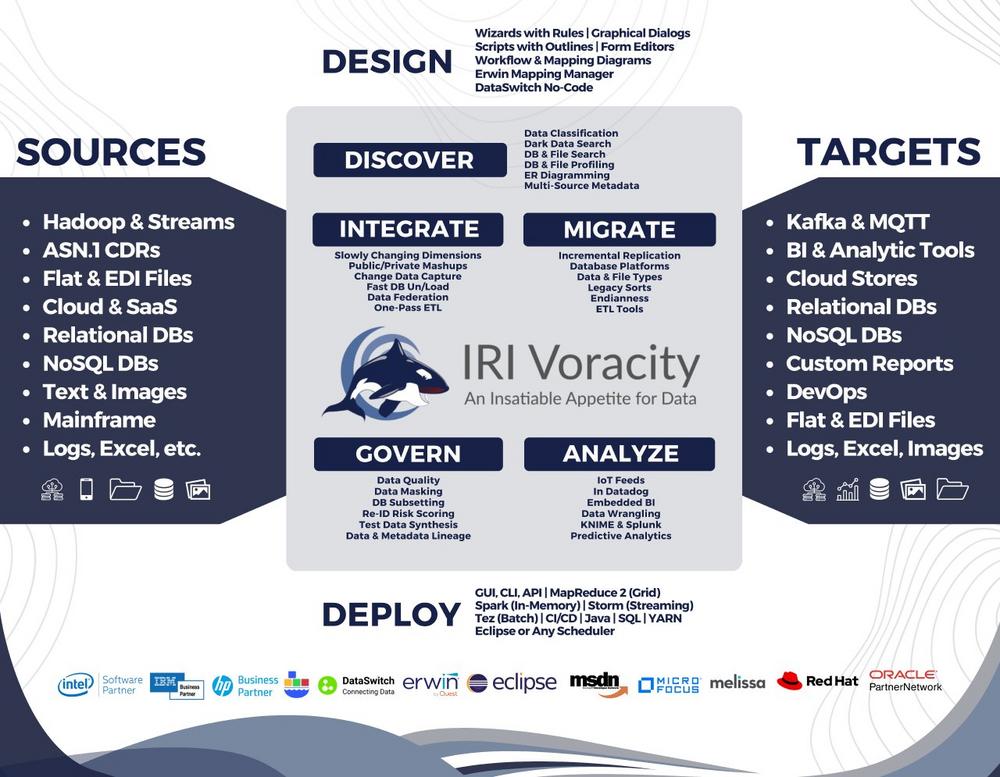
Gezielte Datenübertragung und Datenreplikation: Change Data Caputre (kurz CDC) leitet Rohdaten von Produktivsystemen zu Analyseanwendungen um, um diese zu entlasten und Echtzeitdaten bereitzustellen. Dabei werden ETL-Prozesse und Metadaten verwendet, um Daten zu filtern, zu transformieren und zu laden, sowie automatisierte Abläufe sicherzustellen. CDC bietet verschiedene Erfassungs- und Bereitstellungsmethoden, um die Zuverlässigkeit von Datenpipelines zu gewährleisten. Es erfasst Änderungen an Produktiv- und Metadaten, einschließlich Inserts, Deletes und Updates, sowie DDL-Änderungen. Die Zielsysteme reichen von Datenbanken bis hin zu Public-Cloud-Zielen, Data Warehouses, Data Lakes und Microservices. Dieses Jahr wurde die innovative Funktion "IRI Ripcurrent" in die Datenmanagementplattform IRI Voracity eingeführt, um in Echtzeit Änderungen in der Struktur und dem Inhalt von Datenbankspalten…
-
❌ Optimierung von KNIME-Workflows ❌ Datenintegration und Datenanalyse nahtlos beschleunigen ❗
Nahtlose Integration für effiziente Datenverarbeitung: KNIME, eine Abkürzung für "Konstanz Information Miner", ist eine kostenlose Open-Source-Umgebung für Datenanalyse, Berichterstattung und Datenforschung, die auf der Eclipse™-Plattform basiert. Diese Plattform bietet eine modulare Datenpipelinkonzeption für verschiedene Komponenten im Bereich Machine Learning und Data Mining. Ähnlich wie andere Analysetools verfügt auch KNIME über ETL-Knoten zur nahtlosen Integration und Aufbereitung von Daten. Allerdings stehen KNIME aufgrund von Herausforderungen wie großem Datenvolumen, Vielfalt, Geschwindigkeit und Datenintegrität diverse Anforderungen bevor – es sei denn, es wird durch IRI Voracity unterstützt! Aktuell ist es möglich, die Datenaufbereitung und -analyse mühelos zu beschleunigen und zu kombinieren – und zwar in derselben grafischen IDE für Voracity, die ebenfalls auf…
-
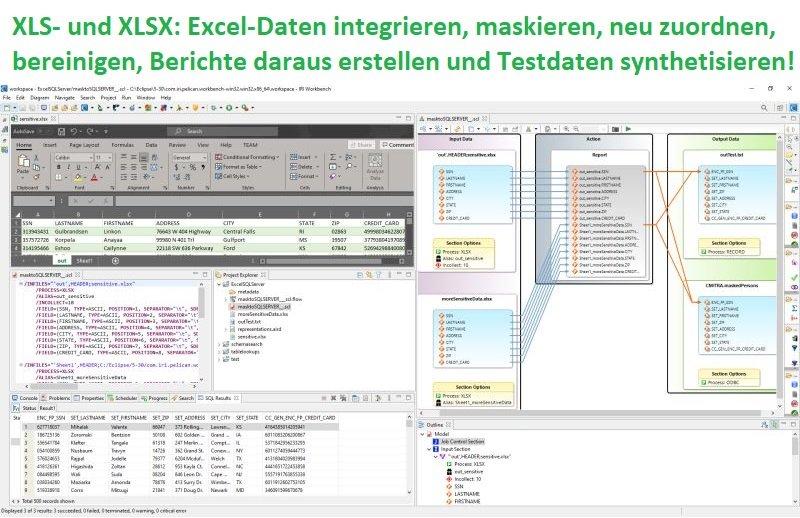
❌ Excel Dateien ❌ Die richtige Datenverwaltung für den sicheren Umgang von sensiblen Daten in Excel-Tabellen ❗
Sind die Daten in den Excel-Tabellen vor einem Verstoß sicher? Hier sind 4 Schlüssel zum Schutz sensibler Daten in lokal gehosteten oder Cloud-Tabellen: Führen Sie eine Datenerkennung in allen .XLS/X-Dateien durch, um klassifizierte Daten wie Sozialversicherungsnummern, Kreditkarten- und Telefonnummern sowie andere Formen personenbezogener Daten auf Spalten- oder (intra-Zell-) Ebene zu finden. Wenden Sie Verschlüsselung, Schwärzung, Hashing oder Pseudonymisierung an, um diese Daten zu verschleiern. Bewerten Sie das Risikolevel, das mit der direkten oder indirekten Identifizierung von Spaltendaten verbunden ist. Führen Sie regelmäßige Audits Ihrer Excel-Dateien durch, um ungewöhnliche oder nicht autorisierte Aktivitäten zu identifizieren. Warum ist dies notwendig? Wenn Laptops in nicht autorisierte Hände geraten oder Computersysteme gehackt werden, sind…
-
❌ Schutz in Dark Data ❌ Datenmaskierung von sensiblen Daten in un/semi/strukturierten Quellen, lokal und in der Cloud ❗
Umfassende Datenmaskierung: IRI DarkShield ermöglicht Maskierung von sensiblen Daten in strukturierten und unstrukturierten Quellen, lokal und in der Cloud! DarkShield Version 5 bietet eine beeindruckende Weiterentwicklung im Bereich Datenschutz und Datenmaskierung, indem es verbesserte API-Engines, eine optimierte Benutzeroberfläche und eine erweiterte Funktionalität für die Maskierung von Datenbanken bereitstellt. Diese Version ermöglicht es Unternehmen, sensible Daten in strukturierten, semistrukturierten und unstrukturierten Quellen sowohl lokal als auch in der Cloud zu finden und konsistent zu maskieren. Eine der herausragenden Funktionen von DarkShield V5 ist die verbesserte IRI Workbench GUI, die den Anwendern eine intuitivere Plattform bietet, um personenbezogene Daten und andere sensitive Informationen zu schützen. Die nahtlose Integration mit anderen Produkten der…
-
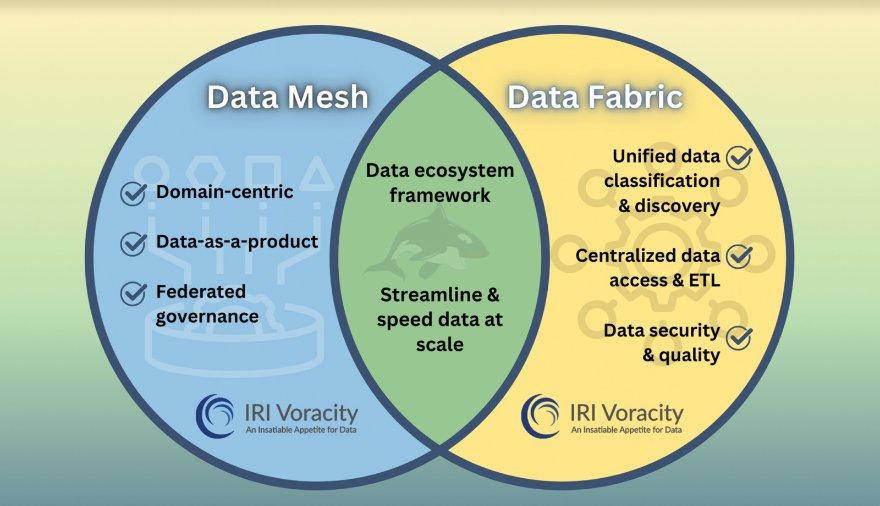
❌ Data Fabric für einfachere Datenverwaltung ❌ Effiziente Unterstützung für Data Fabric-Architektur ohne Zwischenspeicherung ❗
Das Schweizer Taschenmesser der Datenverwaltung: IRI Voracity unterstützt die Data Fabric-Architektur durch direkte Datennutzung und ohne Zwischenspeicherung! Voracity bietet eine breite Palette von Funktionen für Datenintegration, -maskierung und -analytik. Das Unternehmen IRI Inc. ist seit 1978 aktiv, erfand IRI CoSort und beschleunigt die Datenverarbeitung seit über 4 Jahrzehnten! IRI hat Kunden in den Bereichen Bankwesen, Regierung, Gesundheitswesen und anderen Branchen wie Telekommunikation, Einzelhandel und Energie. Zu den Kunden gehören LexisNexis, Fidelity Investments, Comcast und Rolex. IRI zeichnet sich tendenziell in Situationen aus, in denen komplexe Datenverarbeitungen im großen Maßstab erforderlich sind oder PII in mehreren Quellen maskiert werden müssen. Die IRI-Produkte verwenden Datendefinitionsdateien (DDF), um Datenquellen mit Zielen zu katalogisieren…
-
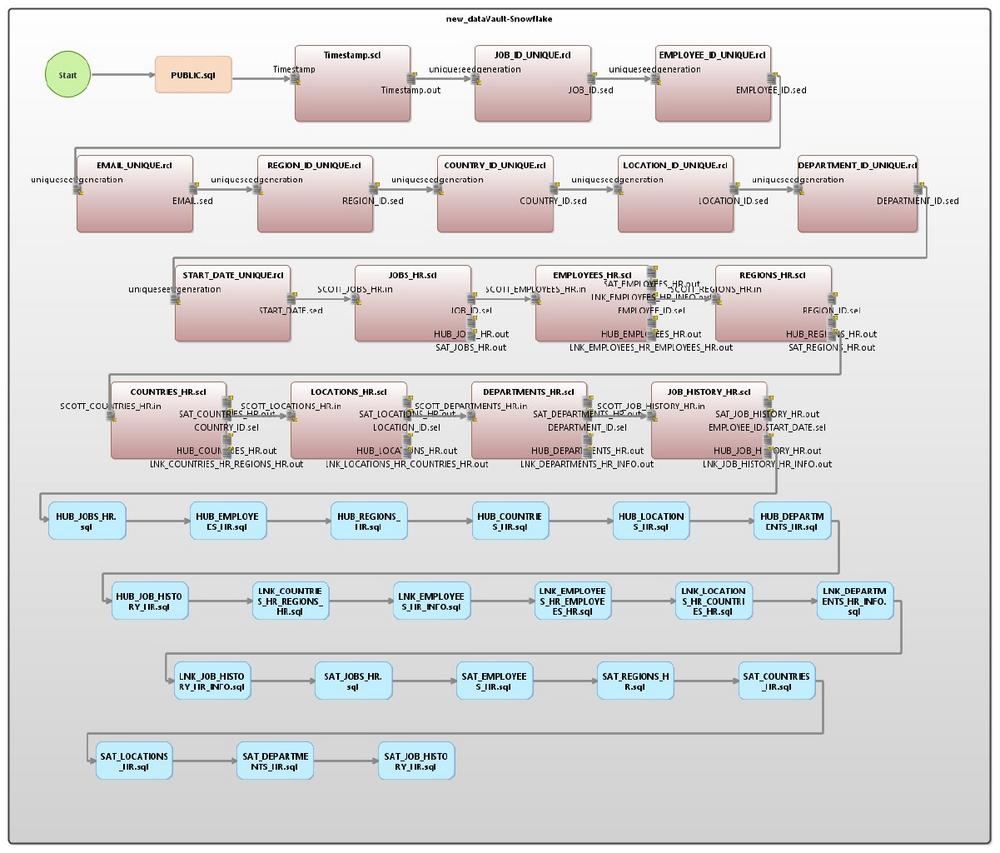
❌ Testdaten für Data Vault ❌ Data Vault Generator-Assistent für realistische Testdaten und sicheres TDM ❗
Realistische und referenziell korrekte Testdaten für Data Vault: Ab CoSort Version 10.5 enthält die IRI Workbench IDE einen Data Vault Generator-Assistenten, der die Benutzer der IRI Voracity Plattform bei der Migration eines relationalen Datenbankmodells in eine Data Vault 2.0 (DV) Architektur unterstützt. Der Assistent hat drei Ausgabeoptionen, die von den Bedürfnissen des Benutzers abhängen. Alle Optionen erstellen das Entity Relationship Diagram (ERD) für die Ausgaben. Die erste Option erzeugt nur die vollständige DDL und ERD. Die zweite Option erstellt eine DDL für Tabellen, die noch nicht existieren, und erstellt außerdem Jobskripte zum Laden der Daten aus den Quelltabellen in die neuen Zieltabellen. Die dritte Option erstellt eine DDL für Tabellen,…
-
❌ Daten für Künstliche Intelligenz optimieren ❌ Verbesserung von Datenqualität und Anonymität für präzisere und konforme KI-Modelle ❗
Daten für KI vorbereiten und schützen: Dieser Artikel skizziert potenzielle Anwendungsbereiche der Datenbereinigungs- und Maskierungslösungen von IRI Voracity zur Verbesserung der Qualität und Anonymität von KI-Modellen. Geeignet sind Anwendungsfälle von reaktiven Maschinen und KI-Modellen mit begrenztem Speicher, die bessere oder sicherere Daten benötigen. Dieses Jahr ist Künstliche Intelligenz (KI), insbesondere Generative KI oder Generative Artificial Intelligence (GAI), zum neuen Liebling der Technologiebranche geworden und hat sogar die Aufmerksamkeit der breiten Öffentlichkeit auf sich gezogen, wenn auch nicht immer positiv. Infolgedessen planen viele Organisationen, sowohl innerhalb als auch außerhalb der Softwarebranche, in naher Zukunft von GAI zu profitieren. Prinzipiell ist dies eine positive Entwicklung. Jedoch besteht die Gefahr, dass Unternehmen in…
-
❌ Datenmigration in die Cloud ❌ Wichtige Herausforderungen und Lösungen für den Datenumzug und die Datenintegration ❗
Herausforderungen und Chancen der Cloud-Datenmigration: Eine moderne Perspektive! Die Einführung von Cloud-Technologien hat die Landschaft für Datenanalyse und KI-Anwendungen revolutioniert, indem sie auch Organisationen mit begrenzten IT-Ressourcen den Zugang zu leistungsfähiger Verarbeitungs- und Speicherkapazität ermöglicht hat. Dies hat zu einer breiteren Nutzung anspruchsvoller Datenpraktiken geführt, die früher nur großen Unternehmen mit beträchtlichen IT- und Datenmanagement-Budgets zur Verfügung standen. Die Verlagerung von Datenarchitekturen in die Cloud ist jedoch kein schneller Prozess. Organisationen müssen sorgfältig überlegen, wie sie ihre Datenverwaltung in die Cloud integrieren und welche Investitionen dazu erforderlich sind. Es bedarf fundierter Entscheidungen, um zu bestimmen, wie die Dateninfrastruktur in der Cloud am besten genutzt werden kann, um die spezifischen Anforderungen…
-
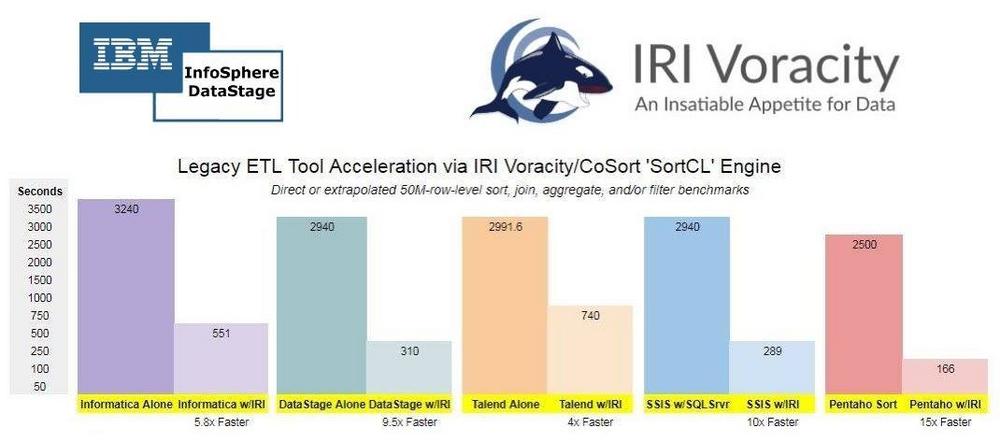
❌ IBM InfoSphere DataStage ❌ Viel bessere Performance und Datensicherheit für die Datenintegration mit IBM InfoSphere Information Server ❗
4 Jahrzehnte Erfahrung im Big Data Management: Trotz Tuning-Maßnahmen bleibt die Transformation großer Datensätze in IBM InfoSpere DataStage zeitaufwendig, insbesondere ohne teure Hardware-Upgrades oder Software-Aktualisierungen. Rechenintensive Aufgaben wie Sortieren, Zusammenführen, Aggregieren und Laden großer Datenmengen können Engpässe verursachen. Die Parallelisierung oder Optimierung in anderen Schichten oder Werkzeugen kann umständlich und kostenintensiv sein und die Leistung für andere Benutzer beeinträchtigen. In Bezug auf die Datensicherheit können die von IBM angebotenen Lösungen zur Datenmaskierung teuer oder umständlich sein und nicht alle Anforderungen für die Identifikation personenbezogener Daten (PII) oder den Datenschutz erfüllen: Beschleunigung von DataStage-Transformationen: Um die Leistung von DataStage zu verbessern, empfiehlt sich die Nutzung von CoSort in einer sequenziellen Dateistufe…
-
❌ Hochwertiges TDM ❌ IRI RowGen liefert realistische und sichere Testdaten ohne Datenschutzbedenken ❗
Vorteile von hochwertigen Testdaten: Datenschutz-Compliance-Gewährleistung: Gute Testdaten anonymisieren personenbezogene Daten (PII) gemäß den Datenschutzgesetzen wie der DSGVO, HIPAA und SOC2. Angemessen maskierte oder synthetische Datensätze werden reale Datenattribute nachahmen, ohne sensible Informationen preiszugeben. Verbesserte Testzuverlässigkeit: Es ermöglicht zuversichtliche, flexible Tests, indem es die Vielfalt, Echtheit und Geschwindigkeit von Daten bereitstellt, die Anwendungsstresstests, Datenbank-/ETL-/Daten-Vault-Prototypen und KI-/Analysemodelle erfordern. Unterstützung für Stresstests und Lasttests: Es kann in ausreichend großen Mengen generiert und zugeführt werden, um die Geschwindigkeit und Skalierbarkeit von Systemen unter Hochlastbedingungen zu testen. Dies stellt sicher, dass Hardware, Software und Netzwerke Spitzenlastzeiten bewältigen können, ohne die Leistung oder Benutzererfahrung zu beeinträchtigen. IRI RowGen zeichnet sich durch seine Fähigkeit aus, realistische…